Planet KDE

Android Java Bindings in Qt 6.7

The Qt for Android plugin, introduced more than a decade ago, has been a game-changing change that opened a multitude of possibilities for developers looking to harness the power and flexibility of Qt for Android application development. Since then, many Android, Qt, and plugin changes have been made to support new features. However, neither the overall architecture nor the public Java bindings have changed much. These bindings contain wrappers for the Android Activity. It is about time we did that!
More Icon Updates
I took some time last week to work on these icons some more. Here are the results:
KDiagram 3.0.1
KDiagram 3.0.1 is an update to our charting libraries which fixes a bug in the cmake path configuration. It also updates translations and removes some unused Qt 5 code.
URL: https://download.kde.org/stable/kdiagram/3.0.1/
sha256: 4659b0c2cd9db18143f5abd9c806091c3aab6abc1a956bbf82815ab3d3189c6d
Signed by E0A3EB202F8E57528E13E72FD7574483BB57B18D Jonathan Esk-Riddell [email protected]
https://jriddell.org/esk-riddell.gpg
Chingam: a new libre Malayalam traditional script font
‘Chingam’/ചിങ്ങം (named after the first month of Malayalam calendar) is the newest libre/open source font released by Rachana Institute of Typography in the year 2024.

It comes with a regular variant, embellished with stylistic alternates for a number of characters. The default shape of characters D, O, ഠ, ാ etc. are wider in stark contrast with the shape of other characters designed as narrow width. The font contains alternate shapes for these characters more in line with the general narrow width characteristic.
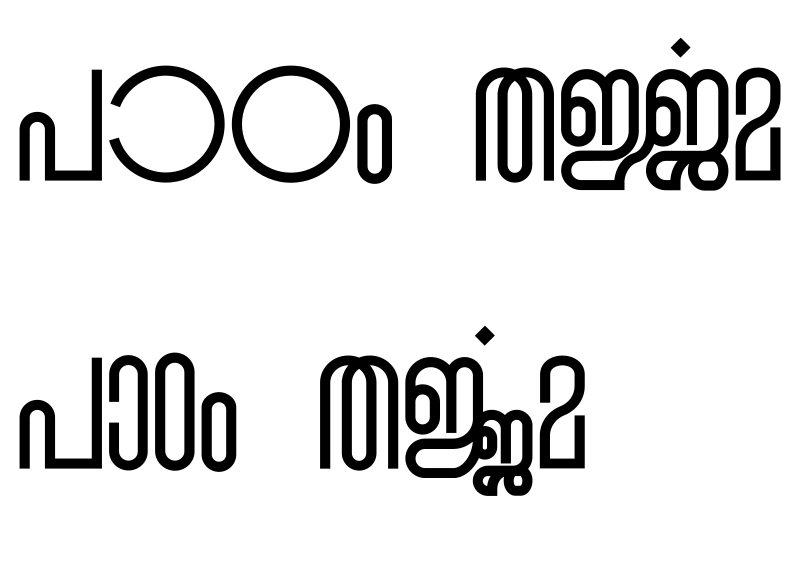
Users can enable the stylistic alternates in typesetting systems, should they wish.
- XeTeX: stylistic variant can be enabled with the StylisticSet={1} option when defining the font via fontspec package. For e.g.
\newfontfamily\chingam[Ligatures=TeX,Script=Malayalam,StylisticSet={1}]{Chingam}
…
\begin{document}
\chingam{മനുഷ്യരെല്ലാവരും തുല്യാവകാശങ്ങളോടും അന്തസ്സോടും സ്വാതന്ത്ര്യത്തോടുംകൂടി ജനിച്ചിട്ടുള്ളവരാണ്…}
\end{document}
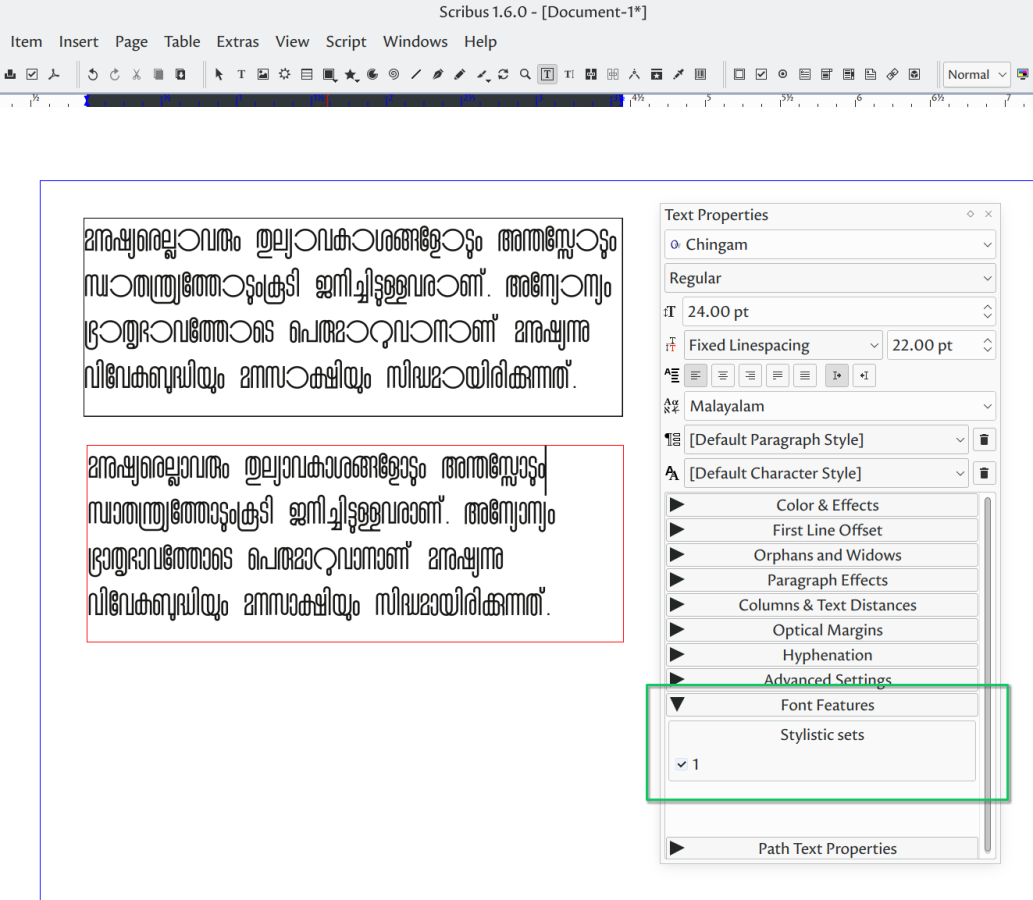
- Scribus: extra font features are accessible since version 1.6
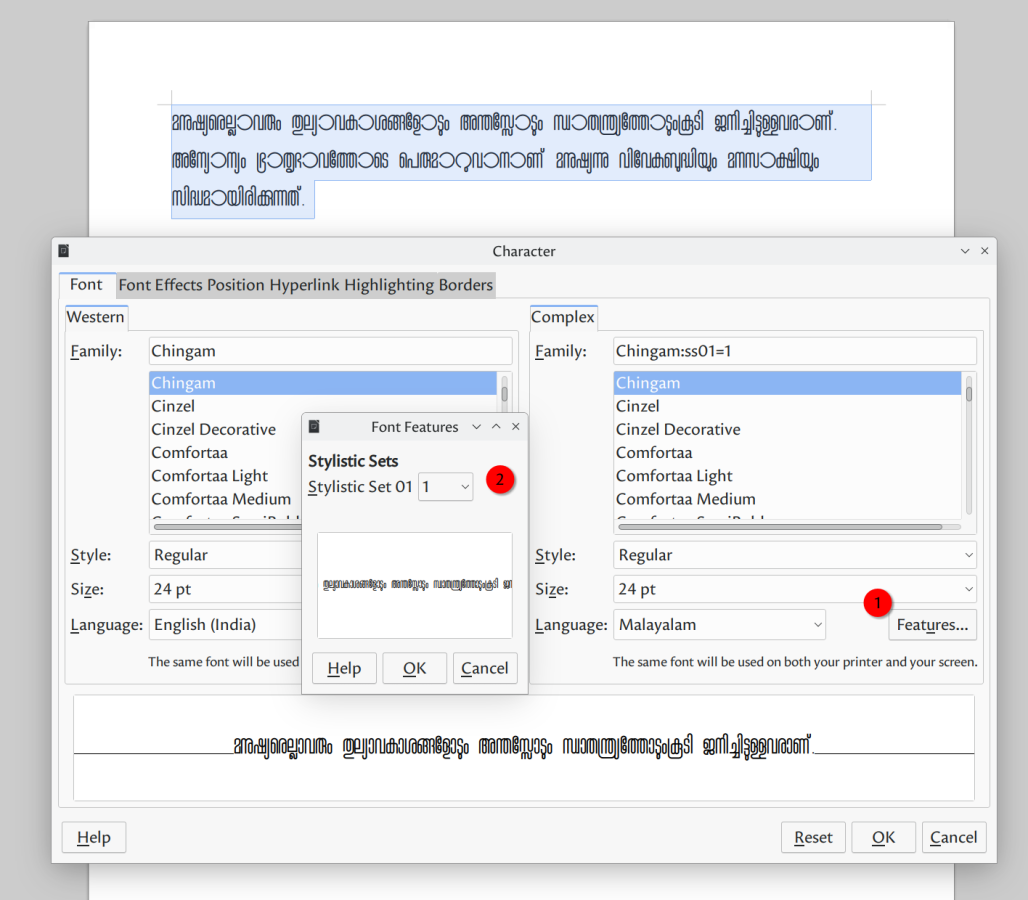
- LibreOffice: extra font features are accessible since version 7.4. Enable it using Format→Character→Language→Features.
- InDesign: very similar to Scribus; there should be an option in the text/font properties to choose the stylistic set.
Chingam is designed and drawn by Narayana Bhattathiri. Based on the initial drawings on paper, the glyph shapes are created in vector format (svg) following the glyph naming convention used in RIT projects. A new build script is developed by Rajeesh that makes it easier for designers to iterate & adjust the font metadata & metrics. Review & scrutiny done by CVR, Hussain KH and Ashok Kumar improved the font substantially.
DownloadChingam is licensed under Open Font License. The font can be downloaded from Rachana website, sources are available in GitLab page.
November and December in KDE PIM
Here's our bi-monthly update from KDE's personal information management applications team. This report covers progress made in the months of November and December 2023.
Since the last report, 35 people contributed approximately 1500 code changes, focusing on bugfixes and improvements for the coming 24.02 release based on Qt6.
Transition to Qt6/KDE Frameworks 6As we plan for KDE Gear 24.02 to be our first Qt6-based release, there's been on-going work on more Qt6 porting, removing deprecated functions, removing support for the qmake build system, and so on.
New featureKontact, KMail, KAddressBook and Sieve Editor will now warn you when you are running an unsuported version of KDE PIM and it is time to update it. The code for this is based on Kdenlive.
ItineraryWhile the focus for Itinerary was also on completing the transition to Qt 6, with its nightly Android builds switching over a week ago, there also were a number of new features added, such as public transport arrival search, a new journey display in the timeline and a nearby amenity search. See Itinerary's bi-monthly status update for more details.

In KOrganizer it is no possible to search for events without specifying a time range (BKO#394967). A new configuration option was added to only notify about events that the user is organizer or attendee of. This is especially useful when users add a shared calendar from their colleagues, but don't want to be notified about events that they do not participate in. Korganizer intercepts SIGINT/SIGTERM signal. It will avoid to lose data during editing.
AkonadiWork has begun on creating a tool that would help users to migrate their Akonadi database to a different database engine. Since we started improving SQLite support in Akonadi during the year, we received many requests from users about how they can easily switch from MySQL or PostgreSQL to SQLite without having to wipe their entire configuration and setup everything from scratch with SQLite. With the database migrator tool, it will be very easy for users to migrate between the supported database engines without having to re-configure and re-sync all their accounts afterwards.
Dan's work on this tool is funded by g10 Code GmbH.
KMailThe email composer received some small visual changes and adopted a more frameless look similar to other KDE applications. In addition, the composer will directly display whether the openPGP key of a recipient exists and is valid when encryption is enabled.

The rust based adblocker received further work and adblock lists can be added or removed.

We removed changing the charset of a message and now only support sending emails as UTF-8. This is nowaday supported by all the other email clients. But we still support reading emails in other encoding.
Now kmail intercepts SIGINT/SIGTERM signal. It avoids to close by error KMail during editing.
Laurent finished to implement the "allow to reopen closed viewer" feature. This provides a menu which allows to reopen message closed by error.
In addition a lot of bugs were fixed. This includes:
- Fix bug 478352: Status bar has "white box" UI artifact (BKO#478352).
- Load on demand specific widget in viewer. Reduce memory foot.
- Fix mailfilter agent connection with kmail (fix apply filters)
A lot of work was done to rewrite the account wizard in QML. Accounts can now be created manually.
KAddressBookBug 478636 was fixed. Postal addresses was ruined when we added address in contact. (BKO#478636). Now KAddressbook intercepts SIGINT/SIGTERM signal. It avoids to close by error it during editing contact.
KleopatraDevelopment focussed on fixing bugs for the release of GnuPG VS-Desktop® (which includes Kleopatra) in December.
- OpenPGP keys with valid primary key and expired encryption or signing subkeys are now handled correctly (T6788).
- Key groups containing expired keys are now handled correctly (T6742).
- The currently selected certificate in the certificate list stays selected when opening the certificate details or certifying the certificate (T6360).
- When creating an encrypted archive fails or is aborted, then Kleopatra makes sure that no partially created archive is left over (T6584).
- Certificates on certain smart cards are now listed even if some of the certificates couldn't be loaded (T6830).
- The root of a certificate chain with two certificates is no longer shown twice (T6807).
- A crash when deleting a certificate that is part of a certificate chains with cycles was fixed (T6602).
- Kleopatra now supports the special keyserver value "none" to disable keyserver lookups (T6761).
- Kleopatra looks up a key for an email address via WKD (key directory provided by an email domain owner) even if keyserver lookups are disabled (T6868).
- Signing and encryption of large files is now much faster (especially on Windows where it was much slower than on Linux) (T6351).
2 bugs were fixed in sieveeditor:
- Fix BUG: 477755: Fix script name (BKO#477755).
- Fix bug 476456: No scrollbar in simple editing mode (BKO#476456).
Now sieveeditor intercepts SIGINT/SIGTERM signal. It avoids to close by error it during editing sieve script.
pim-data-exporterNow it intercepts SIGINT/SIGTERM signal. It avoids to close application during import/export.
37C3 Impressions
A week has passed since I attended the 37th Chaos Communication Congress (37C3) in Hamburg, Germany, together with a bunch of other KDE people.
For the first time KDE had a larger presence, with a number of people and our own assembly. We also ended up hosting the Linux on Mobile assembly as their originally intended space didn’t materialize. The extra space demand was compensated by assimilating neighbouring tables of a group that didn’t show up for the most part.
 KDE assembly featuring the event-typical colorful LEDs and sticker piles (photo by Victoria).
KDE assembly featuring the event-typical colorful LEDs and sticker piles (photo by Victoria).
Just for the logistical convenience of having a meeting point and a place to store your stuff alone this was a big help, and it also made a number of people find us that we’d otherwise probably wouldn’t have met.
TalksThere was one KDE talk in the main program, Joseph’s Software Licensing For A Circular Economy covering some of the KDE Eco work. I’d estimate about 500 attendees, despite the “early” morning slot.
Beyond that I actually managed to attend very few talks, Breaking “DRM” in Polish trains being clearly one of my favorites.
Emergency and Weather AlertsI got a chance to meet the author of FOSS Warn. FOSS Warn is a free alternative to the proprietary emergency and weather alert apps in Germany. That topic had originally motivated my work on UnifiedPush support for KDE, and an emergency and weather alert service that allows subscribing to areas of interest and receiving push notifications for new alerts, covering almost 100 countries.
The latter is a proof of concept demo at best though. The idea is to collaborate with the FOSS Warn team on a joint backend implementation, evolving this into something production-ready and usable for all of us.
While there’s still a couple of technicalities to resolve, after having met in person I’m very confident that this will all work out.
Open Transport CommunityOther groups I’m involved with were present at 37C3 as well, like the Open Transport community, with the Bahnbubble Meetup being the event that brought everyone together.
Discussion topics included:
- Identifying and getting access to missing data tables and documentations for DB and VDV ticket barcodes.
- Helping others with implementing the ERA FCB ticket format.
- Evolving the Transport API Repository.
- International collaboration and networking between the Open Transport communities in Europe,
- Integration between Itinerary and Träwelling.
- Train station identifiers in Wikidata, including a recent property proposal for DB station numbers, as well as a yet to be written one for IFOPT identifiers.
Many more topics ended up being discussed in parallel, overall I’d say there’s more than enough content and interested people for its own dedicated event/conference on this. Until somebody organizes that there’s the open-transport Matrix channel and the Railways and Open Transport track at FOSDEM.
Indoor Localization and RoutingThe OSM community was at 37C3 as well of course, and in that context I got one of the probably most unexpected contacts, by meeting one of the authors of simpleLoc. That’s an indoor navigation solution, which is one of the big open challenges in our indoor map view used in Itinerary.
Like other such solutions it’s unfortunately not fully available as Free Software, but the available information, components and published papers nevertheless turned out very valuable, in particular since this is using a localization approach that requires only commonly available smartphone sensors.
Much more immediately applicable were the hints on how they implemented indoor routing. Unlike for “outdoor” navigation graph-based algorithms are usually not an option, we need something that works on polygons in order to use OSM data as input directly. Existing solutions I encountered for that in a mapping/geography context were all proprietary unfortunately, but there’s a free library that solves that problem for 3D game engines: Recast Navigation.
While I’m not entirely sure yet how to map all relevant details to that (e.g. directional paths for escalators, tactile paving guides, etc), the initial experiments look very promising.
 Routing through a complex indoor corridor.
Routing through a complex indoor corridor.
There’s obviously a ton of work left, as this essentially requires mapping all relevant bits of OSM indoor data to a 3D model, and that’s at the very limit of what can be extracted from the OSM data and data model in many places.
KDE OutreachWhile people working on technology make up a significant part of the audience of 37C3, there’s many more people from other areas attending as well, so this also was an opportunity for a bit of user research, following the pattern of the kde.org/for pages.
KDE for activistsOn the KDE for Activists page we focus a lot on tools for secure and self-hosted infrastructure. The need for that seems like a given or even a hard requirement for people in that field, not something that needs to be argued for (the event itself might provide a certain selection bias for that though).
What we however need to improve on is making this much more robust and easy to setup and manage for people that might not be familiar with all the technical details, jargon and abbreviations we expose them to. Even worse, that can pose the risk of making dangerous mistakes, up to causing people physical harm.
KDE for FOSS projectsMeeting other FOSS developers is also interesting, in particular those not well connected to our usual bubble. That’s often single person projects, some of them even quite successful ones. Around those KDE is then the odd outlier, due to our size and choice of tools/infrastructure (ie. not Github).
Topics that typically come up then are handling of finances, legal risks/liability, shortcomings of Github, moderation of communication channels, etc., all things far less painful from the perspective of someone under the umbrella of a big organization like KDE.
I think there’s some interesting discussions to be had on how widely we want to extend the KDE umbrella and how we want to promote that, what other umbrella organizations there are and whether there are still uncovered gaps between those, and how to manage the scope and governance of such umbrella organizations.
It’s probably also worth talking more about what we already have and do in that regard, it’s not even clear to everyone apparently that joining a larger organization is even an option.
KDE for public administrationWe got questions for pointers to material/support for doing medium-sized Linux/Plasma deployments in public administration. This is unfortunately something we don’t have anywhere in a well structured form currently I think.
It would seem very useful to have, beyond a KDE focus even. There’s people on the inside fighting for this, and while the upcoming Windows 11 induced large-scale hardware obsolescence is working in our favor there, the increasingly pervasive use of MS Teams is making a migration to FOSS infrastructure and workspaces much harder.
ConclusionI had very high expectations for this after the experience at 36C3, but by day 3 this had exceeded all of them. The extreme breadth of people there is just unmatched, coming from FOSS/Open Data/Open Hardware projects tiny to large, public administration and infrastructure, education/universities, funding organizations, politics and lobbying, civil/social initiatives, you name it.
And all of that in a fun atmosphere that never stops to amaze. While walking down a corridor you might find yourself overtaken by a person driving a motorized couch, and if you have an urgent need for an electron microscope for whatever reason someone over in the other hall brought one just in case. And all of that is just “normal”, I could fill this entire post with anecdotes like that.
Ideas and plans for 38C3 were already discussed :)
New Video: Krita 5.2 Features!
Ramon Miranda has published a new video on the Krita channel: Krita 5.2 Features. Take a look and learn what’s new in our latest release:
The post New Video: Krita 5.2 Features! appeared first on Krita.
Two Breeze Icon Updates
Hi all,
I made a couple of videos explaining more updates for Breeze icons. Enjoy!