Our current development model has served us for over 10 years now. We did a transition to Subversion some years ago, and we now use CMake, but basically we still work like we did a long time ago: only some tools have changed slightly. But times are changing. Just have a look at the numbers:
Also, this year's Akademy was the largest KDE event ever held, with more than 350 visitors from every continent of the world.
This enormous growth creates issues both for the wider community, for developers, and for the release team. Patches have to be reviewed, their status has to be tracked - these things become progressively harder when the size of the project balloons like it currently does. The centralized development system in Subversion's trunk doesn't support team-based development very well, and our 6-month release cycle - while theoretically allowing 4 months development and 2 months stabilizing - often boils down to barely 50% of the available time suitable for new feature development.
KDE's current revision control system doesn't allow for offline commits, making life harder for people without a stable internet connection. Furthermore we're still looking for more contributors, so lowering the barrier for entry is another important concern.
We will have to allow for more diversity and we must be able to accommodate individual workflows. Not everyone is happy with a 6-month schedule, not everyone prefers Subversion. Companies have their schedules and obligations, and what is stable for one user or developer is unsuitable for another. Meanwhile, new development tools have surfaced, such as the much-praised distributed revision control tool Git. Together with new tools for collaborating, new development models are emerging. KDE is in the process of adopting a much wider range of hardware devices, Operating systems (OpenSolaris, Windows, Mac OS) and mobile platforms such as Maemo. And we have an increased need for flexible and efficient collaboration with third parties and other Free Software projects.
Sebastian and Dirk believe it is time for a new way of working. In their view, KDE's development process should be agile, distributed, and trunk freezes should be avoided when possible. While there are still a lot of culprits in their proposal, KDE needs to get ready for the future and further growth.
To achieve this, we have to reflect upon our experiences as developers and share our thoughts on this. Our process should be in our conscious thoughts. Sebastian and Dirk talked about a specific lesson they have learned: plans rarely work out. As a Free Software project, we don't have fixed resources, and even if we did, the world changes too fast to allow us to reliably predict and plan anything. We have to let go. We should set up a process aimed at adaptation and flexibility, a process optimized for unplanned change.
This needs to be done in one area in particular: our release cycle. Currently, our release cycle is limiting, up to the point of almost strangling our development cycle. So Dirk and Sebastian propose a solution:
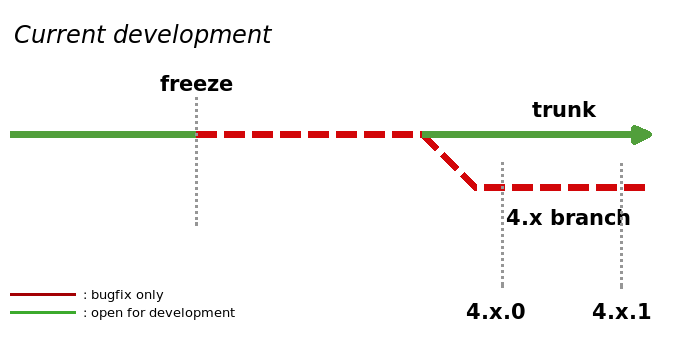
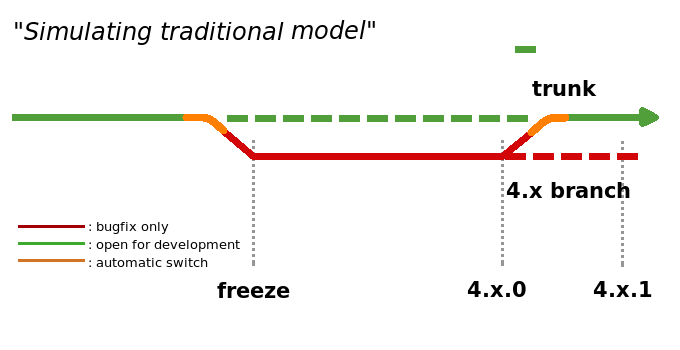
Our current release process, depicted in the graphic below, can be described as using technical limitations to fix what is essentially a social issue: getting people into "release mode". Over 4 months, we develop features, then enter a 2 month freeze period in which increasingly strict rules apply to what can be committed to trunk. This essentially forces developers to work on stabilizing trunk before a release. Furthermore, developers need to keep track of trunk's current status, which changes depending on where in the release cycle KDE currently is, not taking into account diverse time schedules of both upstream and downstream entities. At the same time, many developers complain about Subversion making it hard to maintain "work branches" (branches of the code that are used to develop and stabilize new features or larger changes in the code), subsequent code merges are time-consuming and an error-prone process.
The proposal would essentially remove these limitations, instead relying on discipline in the community to get everyone on the same page and focus on stability. To facilitate this change, we need to get the users to help us: a testing team establishing a feedback cycle to the developers about the quality and bugs. Using a more distributed development model would allow for more flexibility in working in branches, until they are stabilized enough to be merged back to trunk. Trunk, therefore, has to become more stable and predicable, to allow for branching at essentially any point in time. A set of rules and common understanding of the new role of trunk is needed. Also, as the switch to a distributed version control system (which is pretty much mandatory in this development model) is not as trivial as our previous change in revision control systems, from CVS to Subversion. Good documentation, best practice guides, and the right infrastructure is needed. The need for better support for tools (such as Git) in KDE's development process does not only come from the ideas for a new development model though. Developers are already moving towards these tools and ignoring such a trend would mean that KDE's development process will clutter and ultimately become harder to control.
In Sebastian and Dirk's vision, KDE's current system of alpha, beta and release candidate releases will be replaced by a system which has three milestones:
This is the moment we ask all developers to publish the branches they want to get merged in trunk before the release. Of course, it is important to have a good overview of the different branches at all times to prevent people from duplicating work and allow testers to help stabilize things. But the "Publish Milestone" is the moment to have a final look at what will be merged, solve issues, give feedback and finally decide what will go in and what not. The publish milestone is essentially the cut-off date for new features that are planned for the next release.
This is the moment we branch from trunk, creating a tree which will be stabilized over the next couple of months until it is ready for release. Developers will be responsible for their own code, just like they used to be, but one might continue using trunk for development of new features. To facilitate those developers who do not want switch between branches, we could have a tree which replicates the classic development model. Developers are encouraged and expected to help testing and stabilizing the next-release-branch.
The "tested" milestone represents the cut-off date. Features that do not meet the criteria at this point will be excluded from the release. The resulting codebase will be released as KDE 4.x.0 and subsequently updated with 4.x.1, 4.x.2, etc. It might be a good idea to appoint someone who will be the maintainer for this release, ensuring timely regular bugfix releases and coordinating backports of fixes that go into trunk.
A prerequisite for this new development model would be a proper distributed source code management system. Git has already stolen the hearts of many KDE developers, but there are other options out there which should be seriously assessed. Furthermore we need tools to support easy working with the branches and infrastructure for publishing them. Getting fellow developers to review code has always been a challenge, and we should make this as easy as possible. We also need to make it easy for testers to contribute, so having regularly updated packages for specific branches would be an additional bonus. Trunk always needs to be stable and compilable, so it might be a good idea to use some automated testing framework.
Under discussion are ideas like having some kind of "KDE-next" tree containing the branches which will be merged with trunk soon; or maybe have such trees for each sub-project in KDE. Another question is which criteria branches have to meet to get merged into the "new" trunk. Especially in kdelibs, we want to ensure the code is stable already to keep trunk usable. Criteria for merges into various modules have to be made clear. What happens if bad code ends up in trunk? We need clear rules of engagement here. How can we make it as easy as possible to merge and unmerge (in the case the code that has been merged is not ready in time for a release)?
While there are still a lot of questions open, we'd like to work them out in collaboration with the KDE community. KDE's future revision control system is discussed on the scm-interest mailing list. Discussion on a higher level can be held on the Release Team's mailing list, and naturally KDE's main developer forum, kde-core-devel.
With the release of KDE 4.0, the KDE community has entered the future technologically. Though timescales for the above changes have not yet been decided upon, Dirk and Sebastian took the talk as an opportunity to start discussing and refining these ideas: it's time that KDE's primary processes are made more future-proof and ready for the new phase of growth we have entered.
Comments:
Discipline... - boudewijn rempt - 2008-08-28
Well, this frightens me: "relying on discipline in the community to get everyone on the same page and focus on stability", since it's given as the single solution for the problem that quite a lot of people prefer to hack on new stuff they never finish but want to commit anyway. And looking at the disaster that befell KOffice last week, when suddenly KDE trunk started using an entirely different way of linking that completely broke all of KOffice, I doubt there is enough discipline to go around.
And then git... If I look at what happens in the linux kernel development community, I see the best developers being permanently busy with merging, merging, merging and merging and very little else. And, actually, a scheme where we only seldom integrate, where every developer at one, infrequent, moment publishes their branch for merging sounds like a recipe for integration hell, no matter how developer-friendly and good at branching and merging a tool might be.
Re: Discipline... - sebas - 2008-08-28
Certainly true. The "discipline" one is also one of my biggest issues. On the one hand, that would be alleviated by an allegedly less broken trunk, and on the other hand, with better tools, it should be easier to switch to that branch (I'm assuming here that developer reluctance to test release branches has to do with SVN making it hard to switch to a different branch quickly, not from unwillingness). Usually, I see developers taking great pride in their code and want to make sure it looks good when released. Making the rules to merge it stricter would then use the "you want it merged, then first make it work well" mechanism, rather than the "you're on that branch now, either feel the pain of switching branch or fix bugs" mechanism. The first feels much stronger to me.
I guess the real questions is "Why do we have bugs in trunk at all?", and we should work on reducing that.
The Linux kernel development process is not very similar to KDE's of course. The overhead of what's going in is higher, it's quite formal and bound to specific persons that decide it all. KDE is quite different in that it's team-based, so potentially making it easier to share code in those teams and merge it upstream as it becomes interesting for others until finally bugs have been shaken out and it's ready to go into trunk.
Re: Discipline... - Derek Kite - 2008-08-28
>I'm assuming here that developer reluctance to test release branches has to do with SVN making it hard to switch to a different branch quickly, not from unwillingness
I wouldn't come to that conclusion. There are substantial benefits that come automatically from being in trunk that will not happen if branched.
There are a few things in free software that are hard and rare. Development isn't one of them. Testing and code review are hard and rare. Trunk provides automatic access to the rare resources. Limited, but as good as it's going to get. Branches force the developer to build those resources, skills that some may have, some may not. Or more likely, do without.
That doesn't solve the issues at hand however.
What about release in retrospect? Currently development is halted at freeze, which makes out of tree development very enticing, or even necessary. What if each module decided in retrospect the release point? New or major reworks that break trunk could be done out of tree (and having tools that support this would help), and merged at the point where testing and review are desired.
The kernel is different, but testing and review hasn't happened in the spun off branches. One of the problems they face is untested code showing up in merges. Testing and review happens in trunk.
Different targets require their own tree, and having a tool that supports that well would solve the problem.
Derek
Re: Discipline... - sebas - 2008-08-28
Yup, that's one of the points. We need better tools to support more diverse needs and practices. A more staged development process (such as we tried to describe) would be one step towards making this possible.
Re: Discipline... - Cyrille Berger - 2008-08-28
> >I'm assuming here that developer reluctance to test release branches has to do with SVN making it hard to switch to a different branch quickly, not from unwillingness
Well honestly, at least for me, it's not switching branches which I find takes time, or going back to a previous revision, since I often hear "ah with git it is fast", for me it's often 99% of build time for 1% of checkout... With git, darcs, cvs, svn, it will allways be the build time that will makes switch branches, going back to a revision, a pain. Not saying that optimizing the 1% isn't good ;) just that this is not the real main reason for me.
Re: Discipline... - SadEagle - 2008-08-29
I just end up with having multiple entire source + build trees of KDE for this very reason, and for the stable version I don't update outside my work area much, so I can actually build & test a backport in a sane amount of time. A DVCS or such would not do anything to help.
Where things like git do help (from my experiments with git-svn) is in managing in-progress work that's not quite ready for commit, so I don't end up with 50 different patches lying around. Although even there, while branches have low computational load, they still have a high cognitive one...
Re: Discipline... - sebas - 2008-08-29
True. I think the build times are affected quite differently actually.
Also, using git is only part of the picture here. A way to tackle this problem "switching is expensive" within our possibilities is to make it easier to switch to one of those branches. That means documentation, knowing which branch your colleagues are working on, having a good back- and forwardport tool and workflow. And with that goes that we need the right tools to make this cumbersome process as easy as possible.
Switching to a branch at the right point in time actually saves you compilation time as those branches have less and smaller changes compared to the freeze state. Staging the development process also has this effect, less experimenting means fewer / shorter recompiles.
Re: Discipline... - Git - 2008-08-29
May be it's a silly thing, but what about stting up an infraesrtucture of distributed compilation as Icecream for KDE developpers? At least for the more common source tree.
Re: Discipline... - richlv - 2008-08-29
distcc instances that community could donate to developers ? :)
Re: Discipline... - Thiago Macieira - 2008-08-29
Distributed compilation doesn't work over the Internet.
You need a local farm, in your LAN, for that to work. The preprocessed C++ source file is often in the order of several megabytes in size. Uploading that to a machine on the Internet would take too long for most people.
Not to mention, of course, that allowing someone to upload a compiler to your machine and run it is an enourmous security risk. I'd never place my machine in a compile farm whose users I didn't trust.
Re: Discipline... - Thomas Zander - 2008-08-30
Using git you can make the tool do what you want without too much effort, its very flexible.
I set up a workflow for myself using git-svn for koffice where I always work on a branch. And thus my workflow is geared towards making the compile time as easy for me as possible.
The workflow I have seems to be successfull, I compile much less than I did when I was using svn only, and I only have one tree I'm actually compiling in.
I can explain the workflow in another forum, if you want, but I feel confident in saying that in general your worries can to a large extend be managed quite successfully with git.
Re: Discipline... - SadEagle - 2008-08-29
Regarding "less broken trunk": in my experience starting from early 3.0 alpha cycle trunk has always been stable enough for everyday use except during pre-4.0 development. So I am not sure it's a real problem.
Great idea! But who is going to be your Linus? - Tom - 2008-08-28
At first I thought this will be like the kernel development, then I thought it was different, but it really isn't.
Linus tries to have his tree in good shape all the time. But his tree would correspond to the KDE release trees. And linux-next = kde-next.
And the various parts of the kernel have maintainers too.
Only question is who is going to be KDE DVCS benevolent dictator for a period of time (KDEDVCSBDFAPOT) ?? Will he/she be elected?
Damn, it would really help if you would release the Akademy videos or did the dog ate them? Maybe watching Dirk and Sebas would answer my questions.
Re: Great idea! But who is going to be your Linus? - sebas - 2008-08-28
No benevolent dictator, just more strict rules and better review to get your code into trunk. Review by the community and people who care (but you should try harder to find someone to review it, not just hope that no one finds issues within two weeks -- which also could mean "make it hard to review and it's more likely to go in" -- bad idea.
Very interesting WRT review and vcs tools is Ben's blog about it: http://benjamin-meyer.blogspot.com/2008/08/code-review-should-be-free.html
It confirms that our current review process is about as inefficient as it could possibly be.
Re: Great idea! But who is going to be your Linus? - Ian Monroe - 2008-08-29
We may be using a DVCS: I for sure look forward to easily being able to pull in changes from another Amarok developer that they don't think is ready for trunk.
However KDE is essentially sticking to the centralized model.
Developers from EVERY continent? - Ed Cates - 2008-08-28
Who was the Antarctic contingent? ;-)
Re: Developers from EVERY continent? - sebas - 2008-08-28
We're working on that one, actually. :-)
Re: Developers from EVERY continent? - Liz - 2008-08-28
Not a dev, but a KDE user was in Antarctica for the 2005 season :-)
http://www.fsf1532.com/image/kde_everywhere.png (435Kb)
Re: Developers from EVERY continent? - zonk - 2008-08-28
Probably the penguins.
Re: Developers from EVERY continent? - Michael "Antarctica" Howell - 2008-08-29
LIARS!!!! LIESLIESLIES!!!! LIES!!!! LIES! Lies! lies! LIES. Lies. lies.
I don't think there was a developer from Antarctica.
Git vs others - Peppe Bergqvist - 2008-08-28
This is just concerning tools, so it's very basic. And it's just for information, not to start a flame war of any kind.
This is a comparison of git, mercurial and bazaar and there are some nice piecharts there that shows how many languages are being used and how much.
http://www.infoq.com/articles/dvcs-guide
Mercurial uses 4% Lisp (!) for example.
So from a multi platform kind of view I guess Bazaar is the stuff to use, but that's just my guess.
Re: Git vs others - Oscar - 2008-08-28
I've tried Darcs. It's not bad. Could be something to have a look at.
http://darcs.net/
Re: Git vs others - kajak - 2008-08-28
bzr is too slow!
Re: Git vs others - Peppe Bergqvist - 2008-08-28
Of course, a troll with no arguments at all..
And what is "too slow"? Slow at creating repos? committing? diffing? branching?
http://laserjock.wordpress.com/2008/05/08/git-and-bzr-historical-performance-comparison/ give you some numbers, but that is just for that particular case.
Re: Git vs others - Ian Monroe - 2008-08-29
bzr svn is hellishly slow and memory hogging. Because of that, despite trying a couple of times, I could never really use it.
So even though it shouldn't be this way, the 'svn' compatibility is very important. KDE devs use Git because they can.
Git is dangerous - I lost part of my work the other day with a failed git rebase interactive command. Mercurial or Bzr might be better, but I don't know, never had the opportunity to use them.
Re: Git vs others - Shawn Bohrer - 2008-08-29
"Git is dangerous - I lost part of my work the other day with a failed git rebase interactive command."
This is a myth. You have to fairly skilled to actually loose your work in git. In almost all cases including yours you can use the reflog to recover your work.
Checkout "git help reflog"
Re: Git vs others - Ian Monroe - 2008-08-29
A myth? It happened to me on Monday.
Re: Git vs others - Ian Monroe - 2008-08-29
Ah ok, so if I was more familiar with the 150 commands I could have recovered my work. Right. ;)
Re: Git vs others - S.F. - 2008-08-29
For such problems, using git-reflog would have saved you.
Re: Git vs others - Ian Monroe - 2008-08-30
The fact that Git commands aren't atomic seems like a major problem though. git-rebase gave an error, and rather then resetting to the previous state it sent my latest commits to purgatory.
When people talk about Git being atomic I suppose they just mean its commits are atomic. There are so many git commands though, its no wonder that there's a lack of quality control.
Re: Git vs others - Evgeniy Ivanov - 2008-09-05
"There are so many git commands though, its no wonder that there's a lack of quality control."
There are a lot of hg or bzr command too (maybe a bit less, but enough). It's not a problem: to work you don't need all of them.
Re: Git vs others - Tim - 2008-08-29
I bet it really isn't that slow. Besides as someone else said build time is the real annoyance when developing.
I'd rather have a slightly slow but understandable VCS any day.
Re: Git vs others - Al - 2008-08-29
> I'd rather have a slightly slow but understandable VCS any day.
Why not have both? Try Mercurial and judge for yourself.
http://www.selenic.com/mercurial/wiki/index.cgi/Tutorial
Re: Git vs others - Aaron Seigo - 2008-08-29
... funny you should mention Lisp. it's a great language that has relatively few day to day users. bzr may well be a good tool, but most people using a DVCS are using git. seeing as it is rather debatable as to which is better between and git and bzr, current usage is important. a lot of KDE devs are already using git (i'm a casual user myself these days), so the ramp up effort for git should be considerably less than with bzr for that reason alone.
and my main concern is that if/when we switch that it interferes with development as people get used to the switch. any change in the toolset we use will cause discomfort and transitional costs at first. keeping those to a minimum is a priority from my perspective.
Re: Git vs others - Ian Monroe - 2008-08-29
Which is actually a good reason to find a DVCS system thats easier to use then Git. I've been using Git with git-svn for about a year and a half now, I still come across confusing situations.
Git has the best SVN support so there are KDE developers using Git which can't really be said for any of the other DVCS's. That's a major advantage no doubt. But it just seems like no one sat down and thought about the UI for Git.
ian@gomashio:~> git-
Display all 133 possibilities? (y or n)
From the little I've seen of Mercurial and Bzr they seem to created with more of a 'vision' of how the user will work with it. And I know Bzr is designed from the start to work with centralized repos (eg launchpad), seems like it might be a closer fit. Dunno though!
KDE switching to Git would make my life a lot easier, half of the problems I have are related to Git and SVN not playing well together. And being able to actually share branches and work directly with others will be great indeed (if git-svn allowed this, we probably wouldn't even need to switch). So I'm not really against the plan at all, just a little worried.
Re: Git vs others - Aaron Seigo - 2008-08-30
> Which is actually a good reason to find a DVCS system
> thats easier to use then Git
git is pretty easy to use these days; i found git annoying to use a couple years back but it's quite straightforward now. so the main issue i see is existing familiarity, tools that can help transitions and availability of people who will do the work.
> Bzr is designed from the start to work with centralized repos
git does just fine with this as well; i'm using this model for some side projects with gitosis on the server side to make that all a bit easier as well.
Re: Git vs others - Peter Plys - 2008-08-29
I see your point, but if we had to take our decisions based on current usage, we would have never chosen CMake, which we know was the best option.
Besides, Launchpad will be released as free software within a year[0]. As apparently it is much better than other hosting services such as Sourceforge or Google Code, we can expect the number of Bazaar users to increase dramatically.
MySQL recently migrated to Bazaar[1]; some other big projects are using Mercurial.
IMHO, we should choose which DVCS to use based on their actual features, easy of use, documentation, future perspectives, etc, and not on the current number of users.
This page seems to be a good starting point:
http://www.infoq.com/articles/dvcs-guide
[0] http://arstechnica.com/journals/linux.ars/2008/07/23/mark-shuttleworth-launchpad-to-be-open-source-in-12-months
[1] http://blogs.mysql.com/kaj/2008/06/19/version-control-thanks-bitkeeper-welcome-bazaar/
Re: Git vs others - Thiago Macieira - 2008-08-29
We will choose the tool based on having developers with expertise to execute the conversion and then maintain the repository. That also includes teaching and helping others.
If you inspect the traffic for the kde-scm-interest mailing list, you'll see there's only one contender.
If anyone is interested in a different DVCS tool, you had better catch up with the last 6 months of work I have put into Git.
Now.
Re: Git vs others - jerry - 2008-08-30
You've shown the *technical* merits of git, and based on the post above there is *emotional* weight behind this direction, but the decision should be made from a *global* perspective.
Quoting the original article:
KDE 0.0 to 3.5 took 420.000 new revisions in 8 years
KDE 3.5 to 4.0 took 300.000 new revisions in 2 years
What allowed such a progression, the technology of the source code control system, or the socially viable concept of "wanting to contribute"?
The same concept applies right up the life cycle.
If changes can to be tested by 10 people, that's great, but if changes can be tested by 10,000 people that's... well, that's open source.
Re: Git vs others - Thomas Zander - 2008-08-30
No, I think you misread the "emotional" part. The point that Thiago made is simply that if you think something not git should be a contender, start doing the legwork. Since KDE will end up with a tool that actually has a conversion done of the >800000 revisions to that revision model.
So, to back your favorite horse, get on it and make it move.
Re: Git vs others - Aaron Seigo - 2008-08-30
let's assume that Launchpad does get released as Free software, that this does result in an increase of bzr users ... how does that event happening sometime in the next year help change either the situation today or give us a reasonable guarantee that it will even catch up with git usage? it doesn't.
moreover, this is not simply about the current number of users globally, it's about the current number of users within the KDE contributor community. which matters to lower the associated costs of transitioning and to ensure we actually have the manpower to do the transition in the first place.
as for features, git has everything i need and then some.
Re: Git vs others - Ian Monroe - 2008-08-30
I actually don't see the relevance of Launchpad at all. Its not like KDE is going to switch to it or that it'd be impossible for Launchpad to have a "insert-SCM-here" backend.
Re: Git vs others - Peppe Bergqvist - 2008-08-29
Lisp is a nice language, I have used it myself in my education. The possibility to alter a running program is very nice and of most importance when dealing with parsing natural language and building phrase tress (for example). So Lisp is great language, but with few users as you say, maybe this can hinder some development of git (don't know since I haven't checked where the code occurs).
Maybe my point is: the less mixture of different languages the easier to maintain, or something.
Re: Git vs others - Thomas Capricelli - 2008-08-31
Mercurial only uses lisp for the emacs integration. Which, of course, makes sense.
Hm... - Hannes Hauswedell - 2008-08-28
Hm... I didnt really understand the new system completely, but the people in charge sound like they know what they are doing.
I hope that things will work out as planned though. Changing the development model completely could also scare people away and cause breakages. The transition period will definitely slow KDE4-Development down for a while.
Maybe such a big change should not be attempted before KDE4 gets "more done" and more widely accepted. I guess that a year from now KDE4 will have succeded KDE3 completely, also (3rd-party-)application-wise. That might be a good point in time to do it....
but - Ian Monroe - 2008-08-29
Arguably SVN is slowing down development now, as explained in the article.
There will be a transition cost of course. Just keep in mind the current "branching sucks" cost that we are paying daily now.
Excellent - Paul Gideon Dann - 2008-08-28
Yay! This has me really excited. I've always been a great fan of the "stable-trunk" model. It's so much cleaner. The Linux and Git projects both have a policy of keeping master more stable than the most recent release (anything unstable remains in "next"). This provides great confidence in the master branch, and would certainly give me confidence to start hacking away, unlike KDE's current trunk, that I've been unfortunate enough to find broken on more than one occasion :(
I've been an avid Git lover ever since I first tried it about a year ago. Before someone claims Git isn't cross-platform, I'll jump in to say that I use Git with Linux, MacOS X, and Windows on a daily basis, and I can testify to the fact that Git works just fine in Windows now :) Oh, and Git is really not hard to learn at all; it just takes a little time to get started. Everyone should be taking time to learn the tools they use anyway if they want to be efficient. Learn to touch-type and you'll be more efficient; learn Git and your code will love you :p
Schedule - Morty - 2008-08-28
From what I see both as a user getting updates and reading comments by developers, a problem seem to be the development schedule. A 6 months schedule sounds like it's neither here nor there. It's both to short and too long, depending on what you work on and how it fits with the current development phase. I think a more adaptable schedule would work better, using a policy of dual release schedule. But still retaining the freeze periods, making it less relying on developer discipline.
Something like a 4 month schedule, but with the option for selected modules to skip to a 8 month schedule, and instead releasing the latest from the previous stable branch. This will give the developers shorter time to market when the development process are at a stage where small incremental changes makes the most sense. And still have the ability to calmly work on bigger things when the need are present.
Re: Schedule - markc - 2008-08-28
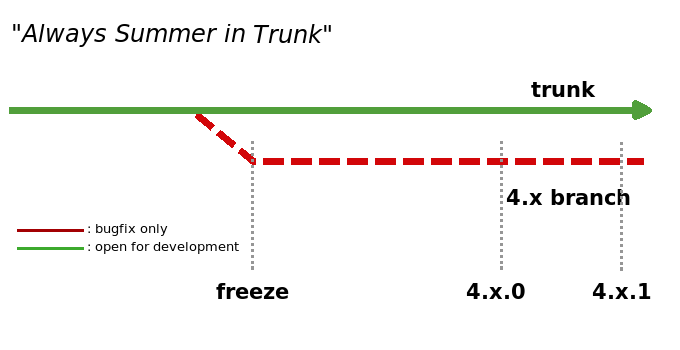
Well if the "always summer in trunk" principle is adopted then, in theory, one could take a snapshot of trunk any old time and release binaries that would most likely at least build and run. The necessity of a release schedule diminishes in importance. I'd say a 3 month official release schedule could be feasible where the last 2 weeks is focused on bug-fixes-only and intense testing of trunk builds. If the released tarballs prove to be a disaster then it would only take a week or two to release a fixed followup release.
Part of the problem with longer release cycles is that the buildup of future changes during the stabilizing phase become so intense that the impedance mismatch between the previous and next versions, particularly at the crossover point just after a release, is in itself a hugely destabilizing factor. With more frequent release there is not such a great leap between the stabilized code and the pent up changes about to rush into the next release cycle leading to less time spent patching things up after each release and more time developing code against a well known and highly usable trunk up until the next bugs-only-freeze stage.
Re: Schedule - Morty - 2008-08-28
As it is there are not often that KDE trunk already at least build and run, so that would not change much. Afterall it's simplest form of developer discipline, don't commit things that don't build. The major problem with "always summer in trunk" is that it relay on more developer discipline, when it comes to stopping and concentrating on bug fixing. A freeze period makes it less a issue, as it to some extent forces it. And it's basicly what you suggest anyway, just without calling it for what it is.
Part of the problem with short release cycles is that there are features that you don't have time to finish and stabilize in a satisfying degree. Either leading to rush them in before release creating lots of problems, or in a state where they never get committed as it's never time to sync and stabilize them with head in a sane way.
Since KDE is a very large project there will always be parts that are in state where it's feasible to do small incremental changes fitting to a short release cycle, and other parts where larger more time consuming changes are needed. With a dual release cycle, developers of the different modules can decide and plan their development efforts accordingly.
To make up an example. For instance the Plasma developers may have lots of small features and fixes that is possible to stabilize quickly and they want to push those out to user as son as possible. While the PIM developers may want to port the whole module to use Akonadi and perhaps do some refactoring, needing more time to implement it correctly and stabilize it compared to the Plasma developers. A dual release schedule would accommodate this, taking into account the different needs of both cases.
Re: Schedule - markc - 2008-08-28
Point taken but if the release cycles are short enough then the parts of the system that take more work can skip a release and not be stuck with becoming too stale by the time that new functionality does get released to the public.
Say a developer, or team, is working on a large subsection using Git then they can keep working amongst themselves during any bugs-only-freeze and sync up with trunk after only a dozen or so days of isolated work. They can then hook up with the next release cycle instead of holding back the current one if he release cycle is short enough.
Re: Schedule - Sebastian Kuegler - 2008-08-28
You could translate the "always summer in trunk" idea to "the last stable version of my code is in trunk".
I think for developers, it's a great asset to know that the features in trunk can actually be expected to not be work in progress anymore. Less uncertainty when you run into the unavoidable question "is this my code that's doing something wrong, or has this just not been implemented yet". If you got it from trunk, it should work. Otherwise, get the developer in question to fix it (or fix it yourself).
Re: Schedule - Paul Gideon Dann - 2008-08-29
Sebastian really knows what he's talking about :) The whole purpose of the master (or trunk) being always stable is that you can tag and release master at pretty much any arbitrary time without concern for instability or bugs.
With the suggested model, a release can be made whenever the release team wants, without affecting the developers at all. Developers continue to produce bug-fixes and features, which are only merged to master when they're stable enough for release. This model really works, and it's wonderfully elegant.
tool replacement cycle - David Johnson - 2008-08-28
I'm still not sold on the idea that we need a new revision control tool every two years. Yeah, some people don't like subversion. So what? Some people don't like git! You will never find one tool everyone likes, but I guarantee you that switching to a new tool every two years isn't going to please everyone either. Let's just skip git and jump directly to 2010's tool!
I understand the desire for a distributed development process, but I'm not sure changing the way everyone works is the only way to get it.
Re: tool replacement cycle - markc - 2008-08-28
The current DVCS options did not exist 2 years ago when the (right at the time) choice was made to adopt Subversion. Now there are 3 or more good contenders for fully distributed version control systems available, and more importantly, the concept of how to use a distributed system is now widespread whereas it wasn't "back then".
There is a reasonable upgrade path towards adopting Git, in particular, by using git-svn as a bridge for a year until it's decided to, hopefully, adopt Git as the central repo as well. There is nothing stopping developers using Git right now and taking advantage of fast branching for themselves and to push/pull between other developers also using Git, then eventually merge with the central master Subversion repo. If after ~12 months experience, of developers using this hybrid approach, that it was decided that Git should also replace the central master repo then you can be sure it would be the right decision... and not just a fad because because the kernel guys are doing it.
Re: tool replacement cycle - Paul - 2008-08-28
You got it backwards.
The objective is not to change the way everyone works to get git. The objective is to adopt git so that they can change the way everyone works.
As TFA says, they are considering other DVCS that support the "always summer on trunk" development model. Git just happens to be the one everyone is familiar with because of the integration with subversion.
Re: tool replacement cycle - Michael "+1" Howell - 2008-08-29
I can agree with that. It's also a matter of the fact that I particularly LIKE the model we use. I know it's got it's downs, but it's got it's ups to.
<rant size="big">
The advantage it has is also it's disadvantage: it's centralized. That means that it's easier to keep all developers on the same page. Because of this, it's also easier to test the whole code-base. If everything is going on in different branches, it's extremely difficult to get the testing that you get when all the development happens in one place.
There is also the pain of merging. Sometimes, a development branch may diverge from the original code-base too much to merge it with the other branches. Depending on the extent of the diversion, you may end up picking a branch, and basically rewriting all the changes implemented in the other branches on it. Naturally, such merging is going to cause serious problems with the large amount of people working on KDE (no, don't cite the Linux Kernel: it follows a model with only a few select people having commit rights who can easily collaborate to ensure merging works easily).
</rant>
Re: tool replacement cycle - Paul Gideon Dann - 2008-08-29
Hmm. I think you're still thinking too centralised. With a decentralised model, there would be a hierarchy of maintainers rather than a central codebase. For instance, if you want to work on KDE-Games, there would be a maintainer for each (maintained) game, and an overall KDE-Games maintainer. If you create a patch for a game, you send it to that game's maintainer, who merges it. The KDE-Games maintainer will pull changes from each game maintainer, and a global KDE maintainer will pull changes from him. The patch is propagated up the chain in this way. The global KDE maintainer will probably also be responsible for release.
You'll find that merge conflicts are pretty rare in this model. I think this is largely because the emphasis on frequent incremental merging (both up and down the hierarchy) prevents any branch from becoming too separated from its parent. In SVN, the emphasis is on large branches that are only merged right at the end, and that is certainly tough.
Re: tool replacement cycle - Ian Monroe - 2008-08-29
Is this actually the proposal?
Re: tool replacement cycle - Thiago Macieira - 2008-08-29
No.
The proposal for KDE is to still maintain a central repository.
Re: tool replacement cycle - Carlo - 2008-08-30
This is the way a see such a system working. Having maintainers of different modules _actively_ maintain these - and this wasn't the case with KDE 3 thoroughly - would do KDE good, because if such a maintainer is slacking or doing bad work, it'll be noticed rather quickly, since developers will complain when stuff doesn't get merged and merging or code quality issues fall directly back to the maintainer of a module branch. It's more hierarchical in the sense that there's more responsibility on different levels and should help to improve overall code quality.
Re: tool replacement cycle - Paul Gideon Dann - 2008-08-30
Hmm; I guess this wasn't touched on specifically in the article. It's the model the Linux kernel uses, and generally seems to be the most logical and elegant model for large projects. I'd be really disappointed if KDE switched to DVCS only to keep the SVN-Wiki model of repository management.
Re: tool replacement cycle - sebas - 2008-08-29
The changes you describe would need to be done in a branch anyway. With SVN, you'll quickly tear your hair out when you need to merge multiple times to keep up with trunk.
Re: tool replacement cycle - Aaron Seigo - 2008-08-30
i don't think we're actually talking about stepping away completely from a centralized model here, but making development in branches or decentralized prior to merging easier.
we 'fake' this fairly well with plasma right now with feature branches and playground, but it's rather painful (to say the least).
> it's extremely difficult to get the testing that you get when all the
> development happens in one place
for plasma, where we do use branches to keep some of the more invasive or experimental changes away from trunk for safety purposes, it's actually the opposite. those branches get nearly no testing except by the involved developers until merging due to the cost and annoyance of trying other branches, and more people stick with the last stable branch versus trunk because of all the raw devel happening there.
i'm hoping we can have a small number of hot branches folding code at stabilization points back to a warm trunk on a regular basis. so everyone can follow trunk and be at most a couple weeks behind the bleeding edge where the developers live. the developers can find and fix the problems they run into, and the rest of those who follow kde's mainline can test the results of that process a few weeks behind.
> a development branch may diverge from the original code-base
well ... don't let them diverge so much then. it's a matter of coordination, and we'll have the main share repo to help with that. that said, svn gives merging branches a really bad name, worse that it actually deserves.
Always summer in trunk - markc - 2008-08-28
Some good arguments for DVCS in general, and Git in particular, is made in this article by Assaf from apache.org who is currently "stuck" with a centralized Subversion repo. A similarly large project in a similar situation...
http://blog.labnotes.org/2008/04/30/git-forking-for-fun-and-profit/
"Always summer in trunk" is the important principle, regardless of dVCS, and what toolset best enables that principle is debatable but Git, IMHO, has the edge and probably the best future inertia. To me, where Git best aligns with KDE over the long term, is it's significant C code base (other contenders being python based) which could become the core of a future C++ Qt/KDE development frontend, perhaps as part of Kdevelop, and provide the best KDE specific workflows. If a python based solution is adopted then KDE is forever locked into having a significant part of it's infrastructure always dependent on python, which is fine by some and not so by others, but those python parts will probably never get translated to C/C++ libraries that would make for the most efficient backends to KDEs C++ frontend. There may be some short term gains with another dVCS but over the long term (5+ years), as various native C++ frontends develop for whatever dVCS is deployed, I believe Git would provide the most powerful backend bindings for a C++ project like KDE.
There is also a GitTorrent project underway and that would help with a large multi-gigabyte project like KDE, and also illustrates the adoption range of Git.
Re: Always summer in trunk - Al - 2008-08-29
Having to choose your VCS based on the language it is implemented is debatable, to say the least.
The only program _remotely_ affected would be Kdevelop, and seeing the good Mercurial support available for Eclipse and Netbeans I doubt it...
If you want to make a well thought decision look at the work some people did when trying to decide what to use.
http://weblogs.mozillazine.org/preed/2007/04/version_control_system_shootou_1.html
http://www.opensolaris.org/os/community/tools/scm/history/
PS: People seems to jump into the wagon "This is good because Linus made it". Please, lets made informed informed decisions based on facts, not on philias and phobias.
Re: Always summer in trunk - Aaron Seigo - 2008-08-30
> People seems to jump into the wagon
that's not what we've been doing; KDE rejected dvcs as an option 3-4 years back, and have arrived at git only after looking at all the options and the skills and manpower we have available to us.
Linus, or any other bandwagon chase, has bugger all to do with this.
Re: Always summer in trunk - Michael "Distributed" Howell - 2008-08-29
GitTorrent? You can't get much more distributed than that ;)!
Re: Always summer in trunk - Ian Monroe - 2008-08-29
Git isn't a library. Judging VCS by language choice is ludicrous. This is actually points in Mercurials favor which actually has a API I believe. And python libraries can easily be accessed in KDE with Kross.
Re: Always summer in trunk - Aaron Seigo - 2008-08-30
yes, hg and bzr both have good APIs. there is a git library, however, and i believe that qgit uses it even? it was a SoC project last year.
but yes, the language the vcs itself is written is isn't really important. (though it can impact things that are, like performance)
Re: Always summer in trunk - Paul Gideon Dann - 2008-08-30
I've done a bit of hacking on QGit and I'm afraid it uses output parsing just like everything else. There was a little work done on a libgit, but the general consensus is that maintaining such a library would be costly, especially as it would make internal restructuring of Git code difficult. Anyway, no official libgit on the immediate horizon as far as I'm aware, but the command-line interface is very parsable (if that's a word), and works fine as an API generally.
There are plenty of Git tools around. All of them use command-line parsing, and none of them has any real problems with it.
Makes an awful lot of sense - T. J. Brumfield - 2008-08-28
I think it will help a great deal.
Big flaw in my view: lack of continuous testing. - SadEagle - 2008-08-29
Right now, with the open trunk model, everyone who is using trunk is using and testing development versions of every application they use. So if I find a bug in, say, Kate, I can report it via bugzilla, or fix it myself, or fix cooperatively with Kate developers, etc. The same with other people using code I worked on --- just in the last few days I've gotten 4 or 5 very helpful khtml bug reports from fellow developers. OTOH, if there was a "kate-development-branch" or something, I'd have to remember to use that, plus "plasma-development-branch", plus "kwin-development-branch", etc.
Yes, you mention user-volunteer testers, but how will they deal with a mess of branches?
And really, I'd say lack of such testing was the biggest reason for KDE4.0.0 being so disappointing a release. Most developers started using KDE4 way too late in the cycle, and so a lot of bugs weren't seen. I know for my stuff there were a whole bunch of easy-to-fix but high-impact bugs that I was told about about shortly after 4.0.0 was tagged. If more people made the jump to 4 earlier, those bugs won't be in 4.0.0 at all.
Further, I think you're severely underestimating traditional stability of trunk. I don't remember when I started using it daily --- I think late in 2.x cycle as a user, and in alphas of 3.0 --- but as a general rule, it's almost always perfectly useable for every-day work. Developers are already generally using work branches for highly invasive changes, anyway.
Re: Big flaw in my view: lack of continuous testing. - markc - 2008-08-29
Yes, the "traditional" concept of using trunk for development and tagging stable branches has been drifting towards the opposite approach for some time. One of the problems with branches is that they (the target URLs) keep changing over time and it requires extra meta info somewhere to help developers stay on the same page, or same code. If the tendency towards a stable trunk is actively pushed then there is only, or mainly, a single long term persistent target URL that any developer, or packager, needs to know about... HEAD, and the more folks that develop with and build against that single target the more it improves it's visibility and therefor it's quality.
Re: Big flaw in my view: lack of continuous testing. - Michael "+1" Howell - 2008-08-29
Agree 100%. ++
Re: Big flaw in my view: lack of continuous testing. - Paul Gideon Dann - 2008-08-29
It's a valid concern, but I don't think it'll be a problem in practice. Because of the hierarchical nature of DVCS, developers won't clone from the global KDE maintainer's master branch. They'll clone from, for example, the KDE-Games' maintainer's master branch, which will contain all the latest goodies that aren't yet considered stable enough for general release. This way, KDE-Games developers will be testing KDE-Games daily, but using stable versions of all the other modules. Each module's developers will be testing their module just as before, without it breaking for everyone else. As it's deemed stable, it'll be merged further and further upstream (contributor's private repo => KBounce maintainer's repo => KDE-Games' maintainer's repo => KDE maintainer's repo). By the time it reaches the root KDE repo, it's pretty rock-solid.
I imagine there will be KDE-next snapshots made available as well, which would include unstable features that aren't ready for master yet.
Re: Big flaw in my view: lack of continuous testing. - SadEagle - 2008-08-29
> This way, KDE-Games developers will be testing KDE-Games daily, but using
> stable versions of all the other modules
And that's EXACTLY what I consider the problem. The rest of KDE just lost a large bunch of highly skilled developers as part of its testing pool.
Plus, the idea of Linux-like centralized development model, with a tree-like structure centralized at one point simply doesn't match how KDE community works.
Re: Big flaw in my view: lack of continuous testin - Carlo - 2008-08-30
> And that's EXACTLY what I consider the problem. The rest of KDE just lost a large bunch of highly skilled developers as part of its testing pool.
"testing pool" or victims of the development model?! Nothing stops anyone to create a testing branch, comparably to current trunk and invite developers to use it - but: No one is forced to it anymore.
Re: Big flaw in my view: lack of continuous testing. - Aaron Seigo - 2008-08-30
at least in Plasma, the plan is to use trunk as a continual warm branch that people can use just as they do trunk now but which will lag behind the hot branches by a number of weeks. we'll still get the same testing coverage we do now (or even more, perhaps), but on code that we've used and tested ourselves for a short while. this means people following mainline will still be testing pre-release code, but not "just committed five minutes ago, not complete yet" features.
Re: Big flaw in my view: lack of continuous testing. - sebas - 2008-08-29
In my view, this becomes easier because you can be sure that if you encounter a bug in trunk, it should actually be reported. No "ow, don't report bugs yet, I'm not done" -- that would be a sign that it shouldn't be in trunk/ already. The status of trunk simply doesn't change anymore: It's always the tip of development that should be bug-free.
If you want more unstable, more bleeding edge stuff, then there could be kde-next, a tree that has development versions that are not really done yet, and that will be merged into trunk once they're better. That's basically the plasma and kate and whatnot development branches lumped together.
So the stability of trunk right now is not the main problem, it's the fluctuation and the constantly changing meaning of trunk that is. It makes it harder for people to stay on top of what's going on.
We also need to be careful with "it's worked for years", we're growing faster than we ever did, and the signs say we will for some time. We need to get ourselves and our development process ready for this growth. One of the important aspects of this new development model is scalability of the KDE developer community.
Re: Big flaw in my view: lack of continuous testing. - SadEagle - 2008-08-29
>In my view, this becomes easier because you can be sure that if you encounter
> a bug in trunk, it should actually be reported
Yes, you would not have to worry about in-progress stuff being broken, but
the regressions won't be in trunk.
And I understand your concern about not having to coordinate with 5 zillions of developers, but in my view, quality requires more coordination, not less.
Re: Big flaw in my view: lack of continuous testing. - Thomas Zander - 2008-08-30
> Yes, you would not have to worry about in-progress stuff being broken,
> but the regressions won't be in trunk.
You have to merge at one point ;)
If there are not going to be any regressions in trunk, then we just got perfect. But I doubt that will happen.
There are two extremes; on one side you have the commit to trunk as soon as it compiles (thats actually how some people work right now).
And on the other side is the concept of only committing something when its perfect.
Neither of these extremes are comfortable, and I'm afraid we are working too close to the one extreme that everything always goes to trunk.
The proposal makes the point of moving more to the middle ground of doing much more stabilization of your features before moving it to trunk.
Nobody is suggesting that merging can only be done when the code is perfect, though.
Bottom line; we don't have to go from one extreme to another. There is sufficient gray area to use.
Re: Big flaw in my view: lack of continuous testing. - Paul Gideon Dann - 2008-08-30
Well, taking a look at the Linux kernel, we see that it's extremely rare for regressions to make it to the master branch of Linus's tree. Of course this is more important for the kernel, and it's unlikely that patches will be scrutinised so carefully in KDE, but I think it's very reasonable to expect there to never be any regressions in the master branch if we truly embrace DVCS.
Re: Big flaw in my view: lack of continuous testing. - Thomas Zander - 2008-08-30
The point is that the choice is still up to the developers. Lots of regression tests help there and the kernel probably doesn't get as many testers.
So, kde devs might integrate into trunk when they feel its ready, not waiting till its perfect.
Git support - markc - 2008-08-29
I'm excited by the possibility that KDE might chose Git as it's official DVCS and general overall Git adoption and documentation is one reason to consider it. As a simple and rudimentary test, check the number results of git, bzr, bazaar, mercurial and hg at Google... git returns 10+ times more than any of the others. Also, when it comes time for developer adoption, sites like http://gitcasts.com/ certainly help and there are at least 2 books available for Git (Pragmatic Version Control Using Git & Git Internals) whereas I'm not aware of any printed books for either Mercurial or Bazaar (they may exist but I couldn't easily find any, which is my point).
EBN - Malte - 2008-08-29
Regarding http://www.englishbreakfastnetwork.org/
Are there actually policies to review modules before release that these minor issues that affect code quality get fixed?
Or are there any attempts to continue and expand this testing?
"KDE's current release team has come a long way in finding module coordinators for various parts shipped with KDE, but currently not every module has a maintainer."
We do I find a list of orphaned modules?
Re: EBN - Allen Winter - 2008-08-29
> Regarding http://www.englishbreakfastnetwork.org/
> Are there actually policies to review modules before release that these minor issues that affect code quality get fixed?
Sorta. New code that goes into kdereview should be clean
But no other policies.
> Or are there any attempts to continue and expand this testing?
I'm always adding new tests and refining existing tests.
We have lots of ideas, but little manpower.
> "KDE's current release team has come a long way in finding module coordinators > for various parts shipped with KDE, but currently not every module has a maintainer." We do I find a list of orphaned modules?
The list of module coordinators can be found on TechBase on the Release Team project page.
SVN 1.5 - XCG - 2008-08-29
I've to admit that I haven't used git so far. But to me it sounds like the workflow of git is about same as a feature branch in subversion for every developer. Now making a feature branch in SVN is easy too.
Merging a feature branch back to truck I have felt no so easy so far. Now with SVN 1.5 they introduced merge tracking which is supposed to simplify this process. Has anyone experience with SVN 1.5's merge tracking? Couldn't it help here?
Re: SVN 1.5 - Thiago Macieira - 2008-08-29
It's not.
You're thinking that every developer with a DVCS tool will get one branch where he can play as much as he wants. And, given proper merging abilities (which SVN lacked until 1.5), you can easily merge code from other branches back and forth.
That is correct, but that's not the whole picture.
First and foremost you forgot the disconnected part. You can't commit to Subversion unless you can reach the repository, which is often in a server over the Internet.
Also, each developer isn't restricted to one branch. He very often has a lot of them. Right now I have 28 separate branches of Qt in my workstation: they range from previous stable releases of Qt (to test regressions and fixes with) to branches I created to start working on fixing tasks to research projects.
And that's just my private branches. When I am collaborating with other people in projects, I have more branches. For one project right now in Qt, we are tracking 4 or 5 different branches, each with a different "theme": optimisations, new features, animations, etc. And there's an extra branch which is the merger of all those "theme branches", so that we can get a feel of what it will be when it's done.
Finally, you're also forgetting the ability to undo, redo, and modify your work. Once you commit to Subversion, it's there for life. Removing something from the repository means dumping and reloading it. With a Git, you can undo your commits, change them, squash them together without problems. (You can do that after you've published them, technically, but you shouldn't)
This is actually something where Git is better than Mercurial: in Mercurial, changing the history isn't that simple.
So, no, SVN 1.5's merge tracking isn't the solution. It's definitely a hand in the wheel for the current problems, but not the full solution. If you want an analogy, it's covering the Sun with a sieve.
Re: SVN 1.5 - sven - 2008-08-29
For people who are curious about Mercurial(hg) this is a good source and this chapter explains how to rollback commits http://hgbook.red-bean.com/hgbookch9.html
Re: SVN 1.5 - Kevin Kofler - 2008-08-30
All that stuff is completely unrelated to the "always summer in trunk" proposal which can be implemented just as well with SVN.
Re: SVN 1.5 - Thomas Zander - 2008-08-30
Its actually not; you can't have 'always summer' if everyone just commits his latest thought experiments and every todo item he just came up with for the world to see.
That just doesn't make for a trunk thats usable due to the amount of people coming into our growing community.
So if you read the article more closely you will see that the basis is that people are asked to only commit stuff to trunk when they are done with it. Which for refactors and bigger things means it may be a week or more before you can commit it.
And due to that requirement, thiago's post becomes very relevant. Those tools are essential to a scalable workflow.
Re: SVN 1.5 - Kevin Kofler - 2008-09-01
> Its actually not; you can't have 'always summer' if everyone just commits his latest thought
> experiments and every todo item he just came up with for the world to see.
I don't see why. The current trunk is working fine, the only difference would be that trunk development can continue during a release freeze because the release would be branched earlier, I don't see why that would prevent working on the trunk the same way as previously.
> Which for refactors and bigger things means it may be a week or more before you can commit it.
That's what branches/work is for. Keeping features on a developer's HDD is a very bad idea, it means zero testing, no way for other developers to coordinate their changes, no way to help implementing the feature etc. Basically it's a return to the "big code drop" antipattern which SCMs were designed to solve, and getting the history added after the fact as part of the big push is only a mild consolation (and not even that is guaranteed because git can "flatten" history and that "feature" has been touted as an advantage).
Re: SVN 1.5 - Kevin Kofler - 2008-08-30
Oh, and to reply to your actual arguments:
> First and foremost you forgot the disconnected part. You can't commit to Subversion unless you can reach the repository, which is often in a server over the Internet.
And that's a good thing, as it enforces open development, i.e. people can always test the current development version, nobody has to wait for the developer to "push" his/her changes. Committing to the central repository as often as possible is just a part of "release early, release often" best practices. And the nice thing is that you don't even have to release, just commit and it's automatically public, unlike with a DVCS where you have to explicitly push.
> Finally, you're also forgetting the ability to undo, redo, and modify your work. Once you commit to Subversion, it's there for life. Removing something from the repository means dumping and reloading it.
That's also a good thing, history should not be altered, and people should be able to see the progress of development, it's part of openness.
> With a Git, you can undo your commits, change them, squash them together without problems. (You can do that after you've published them, technically, but you shouldn't)
And that's just evil. And it's also moot because people should be pushing after each commit (remember: release early, release often) unless they have a good reason not to (e.g. being in an airplane).
DVCSes encourage development behind closed doors, and that's a bad thing, because it goes against the community development model which has made the success of KDE and many other Free Software projects. (According to the "Open Source" folks, it's even the main advantage of "Open Source" software in the first place.)
Re: SVN 1.5 - L. - 2008-08-30
Complete agreement...
Besides for the few contributors who can't do without disconnected features, either occasionally or because it matches better their way of working, there already is git-svn.
So what are the arguments for forcing git's horribly steep learning curve on every contributor?
Has the great raise of the bar of entry for the average contributor even been considered?
Re: SVN 1.5 - Aaron Seigo - 2008-08-30
> nobody has to wait for the developer to "push" his/her changes
no, you just have to wait for them to commit their changes. and making branch management easy encourages people to work in published branches and be able to switch between them more.
> And it's also moot because people should be pushing after each commit
i couldn't agree less.
when working on a git repository, i often do a bunch of much smaller commits than i normally would with svn. i can use these as nice "save points" in my local repository without inflicting my work in progress on others in the same branch, while gaining the benefits of being able to save my work as often as i want even when it isn't done.
i end up pushing about as often as i would commit with svn, but i commit far more often with git and it's a great boost to productivity.
combine with squashing, i can make 50 commits in a day to finish one bigger feature and then squash it down to just the three or four important events before publishing to everyone else. or.. i can just push the whole lot if i'm lazy =)
> DVCSes encourage development behind closed doors
that's at least partly why people want to keep the centralized model, even when using git. it's not the tool that encourages closed development, it's the workflow used. with svn there's basically only one possible workflow, with a dvcs there are several including ones that give similar openness benefits.
as for making points moot, i'm not sure if you are aware of how many git-svn users there are out there with all their completely unpublished, unsearchable and un-clonable repositories. i'd much prefer to see these branches publishable to a central location so people don't have to choose between git and sharing, which is exactly what's happening already.
so ... the problem is already here. i'd like to see us deal with it, and improve our workflow in general in the process =)
Make development easy - Jordi Polo - 2008-08-29
If Git is to be used, I __strongly__ recommends taking a look to:
http://www.github.com.
It is a Git hosting service with social networking bits on it.
Also, contribute and fork one owns private branch is as easy as click the "fork" button. Make improving software not interesting but something one can't stop doing!
Re: Make development easy - Thomas Zander - 2008-08-30
Looks neat :)
Is it open source? I liked http://gitorious.org/ as well, which is open source (and so easy to extend and not dependent on a company)
Re: Make development easy - Jordi Polo - 2008-08-30
Cool. Gitorious seems to be the same idea.
Yeah I just supposed that github was open source but it may be not.
It that casa I guess Gitorious is better
Re: Make development easy - Lisz - 2008-08-31
Github is not open source.
Can't wait to see this in use - Bráulio Barros de Oliveira - 2008-08-29
KDE really needs to go in the Linux direction, as it is also a huge and rather dynamic project.
Where are the other akademy news? Only the two first days were published :(
Re: Can't wait to see this in use - Aaron Seigo - 2008-08-30
i think they just stopped calling them "day 1" and "day 2" and started giving the articles meaningful names =)
Re: Can't wait to see this in use - Paul Gideon Dann - 2008-08-30
I agree that KDE needs to go in a Linux direction. I'm gradually become aware, however, that there is a difference between the two projects' methodologies. Linus is the sole owner of the authoritative tree, and has several "lieutenants" that own their trees, etc... However, KDE relies strongly on a large number of equally-important contributors. I'm guessing that the hierarchical model that Linux uses isn't going to map to KDE so well (at least not for the time being). I guess KDE will keep a central repo, with the most active developers having direct push access, and more "fringe" contributors working either on their own repos or in sort of "workgroup clusters" (for those working on the same feature).
The big difference I think, is that there simply isn't one owner of the KDE project, like there is for Linux. Maybe that will change as DVCS methodology starts to take root. It'll be interesting to see.
Related to Akademy.... - Janne - 2008-09-01
When can we see the videos of the various talks that were held at Akademy?
Git vs SVN vs TortoiseSVN - Tanguy Krotoff - 2008-09-05
One thing that should be studied carefully I think, is the tools coming with Git and SVN.
For SVN I've been using for several years the awesome TortoiseSVN (yes works only under Windows...) http://tortoisesvn.tigris.org/
So easy, so simple, TortoiseSVN simplifies all the hard work with a perfect UI.
Try it once, and it will be impossible for you to come back to svn command line.
This the reason I keep with SVN.
Question is, can we expect equivalent tools for Git in the near future?
A good UI above git/svn/... is a good way for "lowering the barrier for entry" and "is another important concern"
Re: Git vs SVN vs TortoiseSVN - joe - 2008-09-05
Already exists for Hg so I think Git will follow
http://tortoisehg.sourceforge.net/