You have probably heard of Nepomuk, the semantic desktop technology we've been shipping for a while as part of the KDE Platform. However, so far, you may not have noticed it really doing very much useful for you. So what is this thing called Nepomuk, what can it do for us now and what will it bring us in the future? We asked two of the driving forces behind Nepomuk, Stéphane Laurière and Sebastian Trüg of Mandriva, to tell us about the real Nepomuk features that are already available in KDE software and those that have been introduced with Mandriva Linux 2010.
The people
Stéphane has been working for Mandriva since 2004 and is working on a variety of projects related to collaborative knowledge management. One of those is
"the integration of the Nepomuk technologies into the Mandriva distribution and on the writing of the specifications of the next features". He lives in Paris and met Ansgar Bernardi (of the
German Research Center for Artificial Intelligence) and Stefan Decker (of the
Digital Enterprise Research Institute in Ireland, author of the seminal paper
The Social Sematic Desktop) in Luxembourg in 2005. This led to Mandriva, DFKI, the DERI and others to devise the Nepomuk project and apply for European funding. The project was selected and work began on 1 January 2006. For Stéphane, Nepomuk is very much a reality today:
"as a user, I switched entirely to Nepomuk for managing my personal notes and the links I maintain between projects, contacts, organizations, ideas etc". Stéphane is working on setting up new research projects to
"ride the semantic wave that is coming :-)".
Sebastian is best known for the CD burning application K3b which he has been developing since 1998. He lives in Freiburg (and seems to like it: "if you ever lived in Freiburg you probably still are - or got forced to another place"). In 2007 he was seeking employment working on KDE technologies and Mandriva, having sponsored him already for K3b, was his first choice: "that is how I met Stéphane who pulled me into the amazing world of the semantic desktop". Since then he's been working on the "first semantic desktop technology in a large free software community, sorry, THE large free software community". In the original research project, Sebastian's role was to make Nepomuk part of the KDE Platform - an integrated, unobtrusive technology that allows application and workspace teams to make their products get smarter in the way they handle your information. He has now taken on a lot of new responsibilities: "I am maintaining pretty much every part of Nepomuk, desperately - but not really successfully - trying to find new recruits to do all my work for me".
An overview of the current status

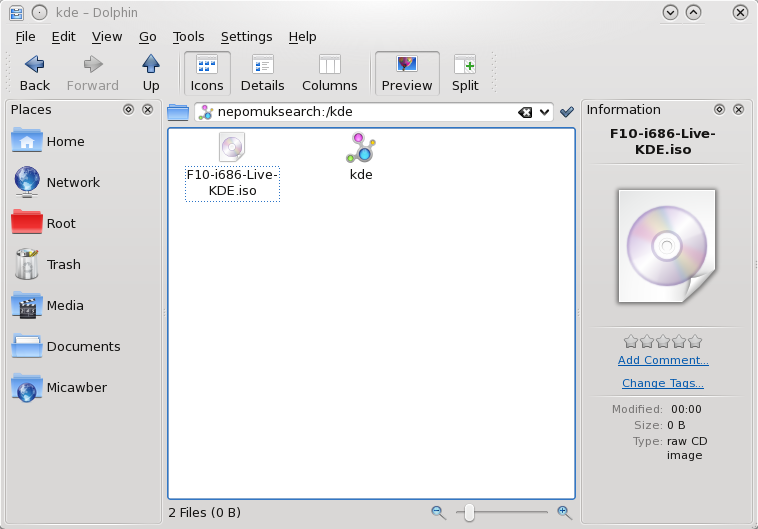
Nepomuk search in Dolphin
So, where are we at with Nepomuk now, compared to where we want to be? Stéphane explains that
"Nepomuk initially aimed at two main achievements: 1) the ability to interlink data semantically on the desktop across the applications, 2) the ability to share semantic information with other desktops". The first is
"getting mature from the infrastructure point of view" and he believes that Mandriva Linux 2010 gives a good insight into the improvements it can bring to the user, but much remains to be done. The design of the framework for the second main objective started only recently:
"a workshop took place in Freiburg early November and resulted in a first draft of the Nepomuk Sharing Ontology, and in a set of sharing use cases". Ultimately, it should be possible to share semantic information everywhere from mobile handsets to enterprise servers so that
"the sky's the limit".
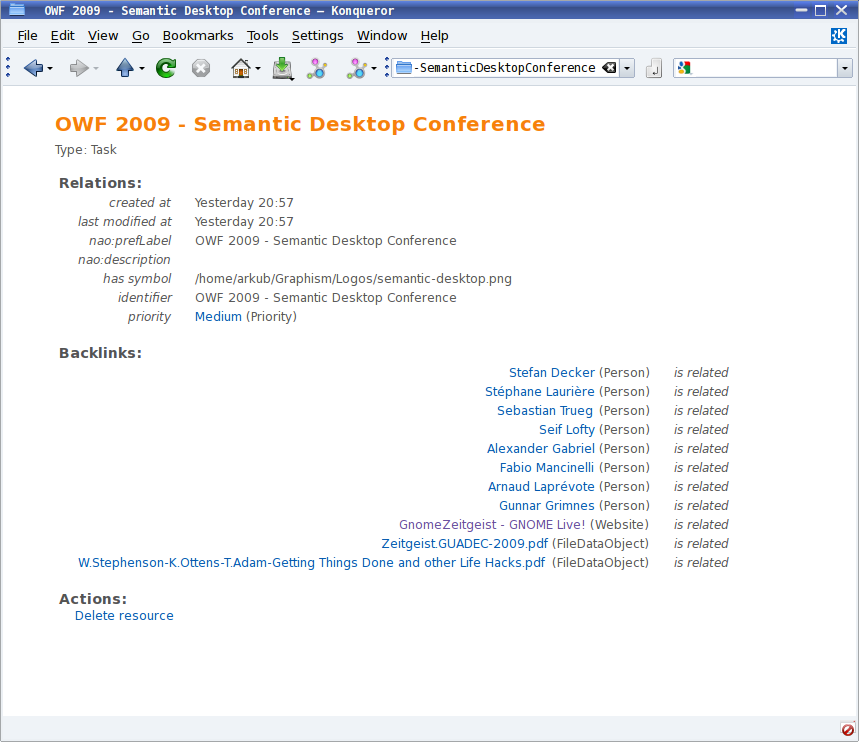
Nepomuk is already there in ways that you hardly notice - when you tag an image in Dolphin that tag is also visible in Gwenview. Obvious right? Well of course, but that is Nepomuk in action behind the scenes.
Using Nepomuk today to find your files
Assuming your distribution has enabled Nepomuk, files can be already be tagged and rated from Dolphin and searching is possible by typing in to the address bar a query such as:
nepomuksearch:/tag:semanticweb tag:project
If it's a search you use a lot you can add the search results to your Places panel, just like a normal folder. However, complex searches can require quite a lot of knowledge of the correct terminology - consider:
nepomuksearch:/?sparql=select ?r where {{?r nao:hasTag <nepomuk:/semanticweb>} UNION {?r nao:hasTag <nepomuk:/p2p>}}
.
Stéphane acknowledges this:
"easier ways to interact with the Nepomuk knowledge base are essential". He notes that
Alessandro Sivieri is adding 'faceted browsing' capabilities to Dolphin:
"this means you will navigate across your files by selecting a combination of filters graphically. For instance: display all pictures that were taken during last Summer, tagged with Italy and where Kate is present".

Preview of the new search interface
With version 4.4 of the KDE Platform there will be a new Nepomuk query API to make it
"very easy for application developers to create query interfaces" and so we should begin to see more use of the Nepomuk capabilities in the applications.
Peter Penz is integrating an improved query interface for Dolphin that should debut with release 4.4 of the KDE Software Compilation. Full faceted browsing based on Alessandro's work is expected in Software Compilation 4.5
But enough of the future features. The bottom line is that you can already use Nepomuk for simple searches from the Dolphin address bar and, with the correct knowledge, far more complex searches are also possible. As Stéphane notes, the introduction of Virtuoso as the default storage technology has increased performance significantly so that it is now "possible to perform live queries, updating search results as the user types or proposing query completion at the same time".
This is all part of the process of transforming Nepomuk from a research project to something that is actually usable in the real world. Stéphane and Sebastian recognize how important the KDE community is in this process: "integration of the Nepomuk APIs in KDE software checks it against the effective needs of the users, makes testing more distributed and more efficient, and offers a perfect place for collaborative creativity". They wanted to express "a big thank you to the KDE community for giving Nepomuk a chance - this shows the real power of open-source in general and especially KDE".
All the code (except a few patches specific to Mandriva integration) is maintained within the KDE SVN so it's easy for anyone to contribute and test.
Nepomuk features debuting in Mandriva Linux 2010
In its latest release, Mandriva has packaged a number of new applications and features based on Nepomuk. These are also developed within the KDE community but are not yet integrated in the KDE Software Compilation although it is intended that they will be at some point in the future. Other distributions are of course free to integrate these experimental features. Let's have a look at them.
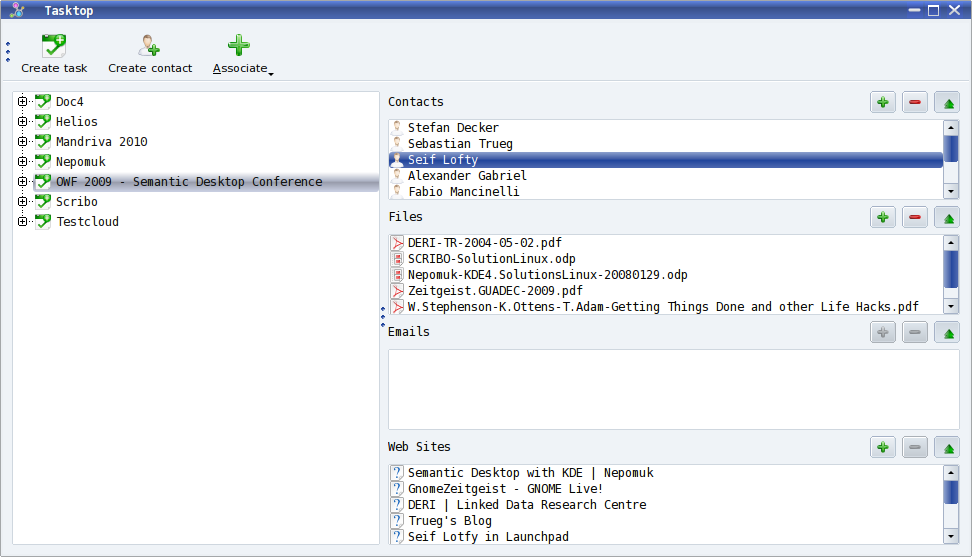
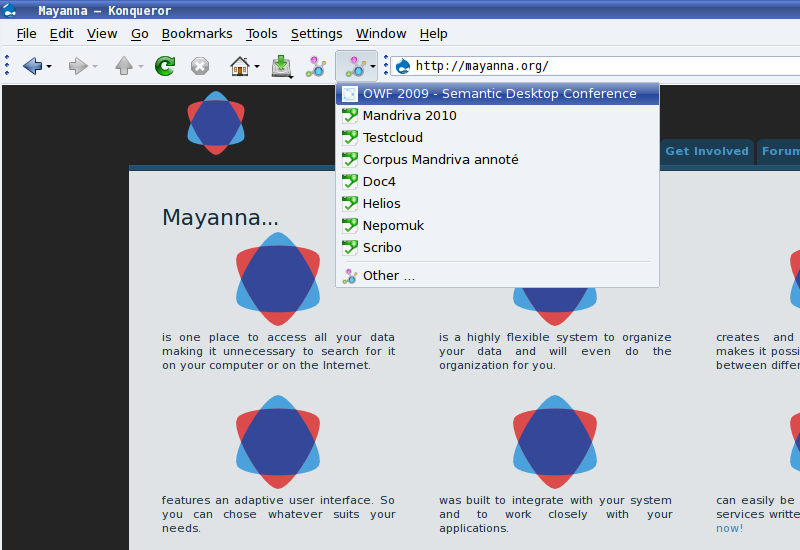
Task Manager and Nepomuk shell
The Mandriva task manager is a general application for managing items that relate to particular tasks, for example files, contacts, emails and web pages. Actions can be launched from the context menu associated to each item. For instance, an email can be sent to all contacts associated with the selected task.

Task Manager
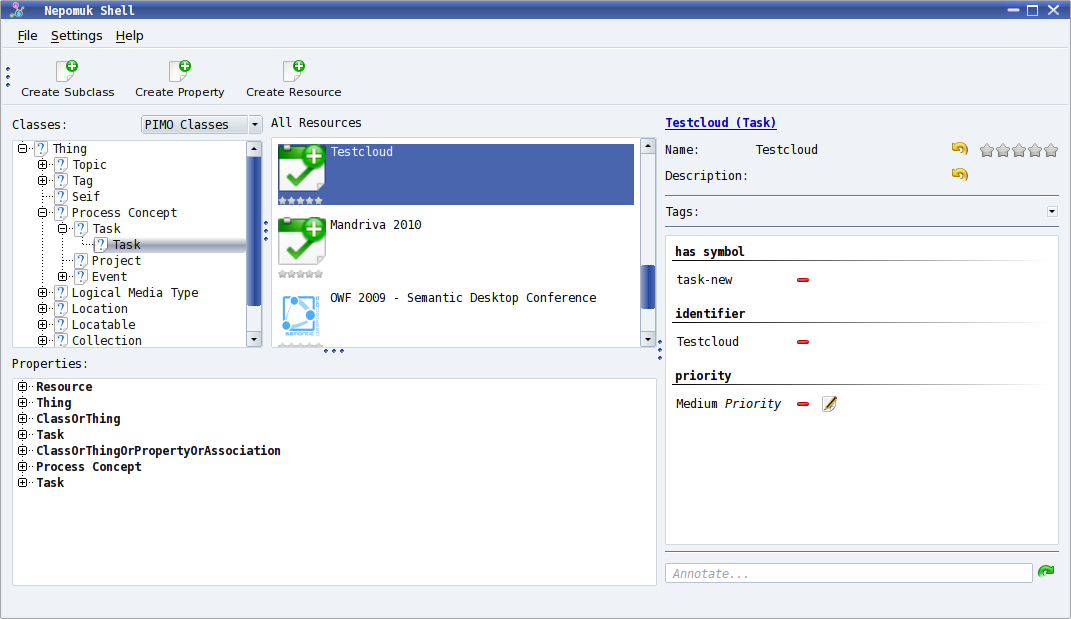
The Nepomuk shell is an application dedicated to the visual management and easy annotation of semantic resources.

Task browsing with Nepomuk Shell
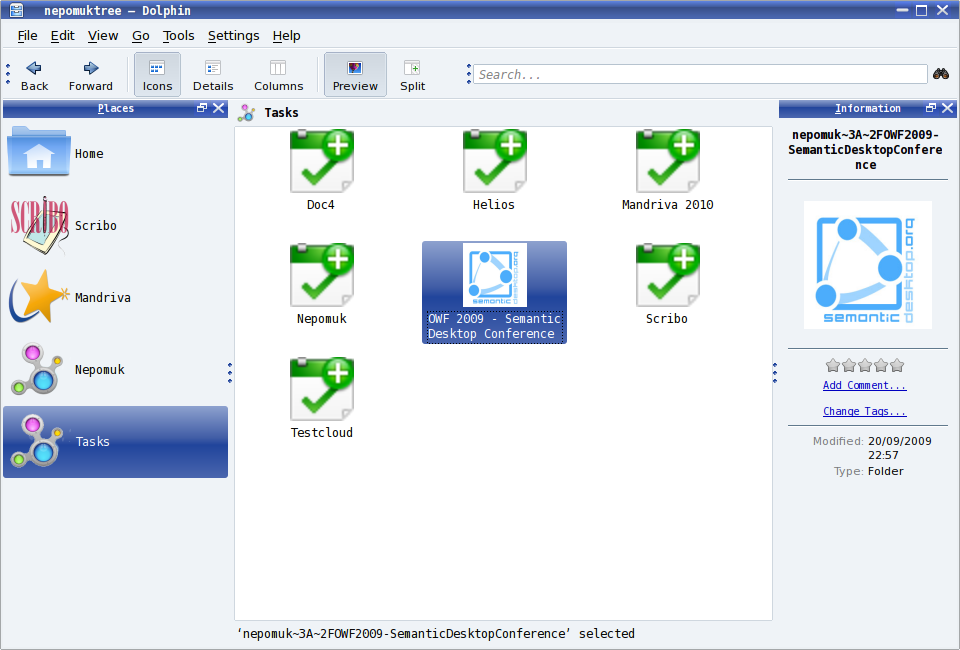
Task browsing integrated in Dolphin and Konqueror
Typing nepomuktree:/ in the Dolphin address bar displays all the tasks and their subtasks, and makes it possible to navigate across the task contents.

Task browsing in Dolphin
You can also browse the tasks using a hypertext based interface in Konqueror:

Browsing items via hyperlinks in Konqueror
Konqueror task plugin
There is also integration with web browsing in Konqueror: a "task button" is provided to let you quickly associate a web page with a task.

Easy tagging in Konqueror
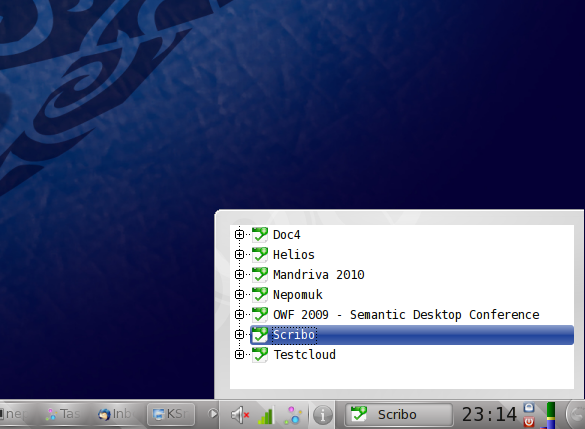
Task Switcher
The Mandriva Linux 2010 workspaces include a widget called Task Switcher from which you can select tasks and create new ones. It lets you see all your active tasks and choose one of them as the current task.
Task Switcher widget
Making tagging easier
Sebastian and Stéphane recognize that "the long term success of Nepomuk hinges on the ease to link and to annotate documents: the cost of adding metadata to documents must be made negligible compared to the productivity gain". With this in mind, they have worked on making tagging as easy and automated as possible in Mandriva Linux 2010
Assisted manual tagging
From Dolphin, right clicking on a file or a Nepomuk resource (such as a file) and selecting the entry "Action > Annotate" makes it possible to annotate the item. For example, let's say you have a contact "John Smith". Typing "John" in the annotation field will propose to link the selected file with your contact John Smith. A modified KMail package, kmail-nepomuk, provides the ability to easily tag emails too.
Automation of tagging
An exciting, but early stage, technology being trialled in Mandriva Linux 2010 is automation of tagging using
Scribo, a research project sponsored by the
System@tic competitiveness cluster. Stéphane and Sebastian see Scribo as
"a natural continuation of Nepomuk: it completes the annotation infrastructure". They imagine a scenario in which you receive an email titled "Scribo meeting at Nuxeo office 10/12/2009". Using Scribo and Nepomuk,
"KMail could offer to add en event to your calendar that is automatically linked to the Scribo project, the Nuxeo company, the map of the Nuxeo office in Paris and to the Scribo participants".

Scribo-assisted tagging
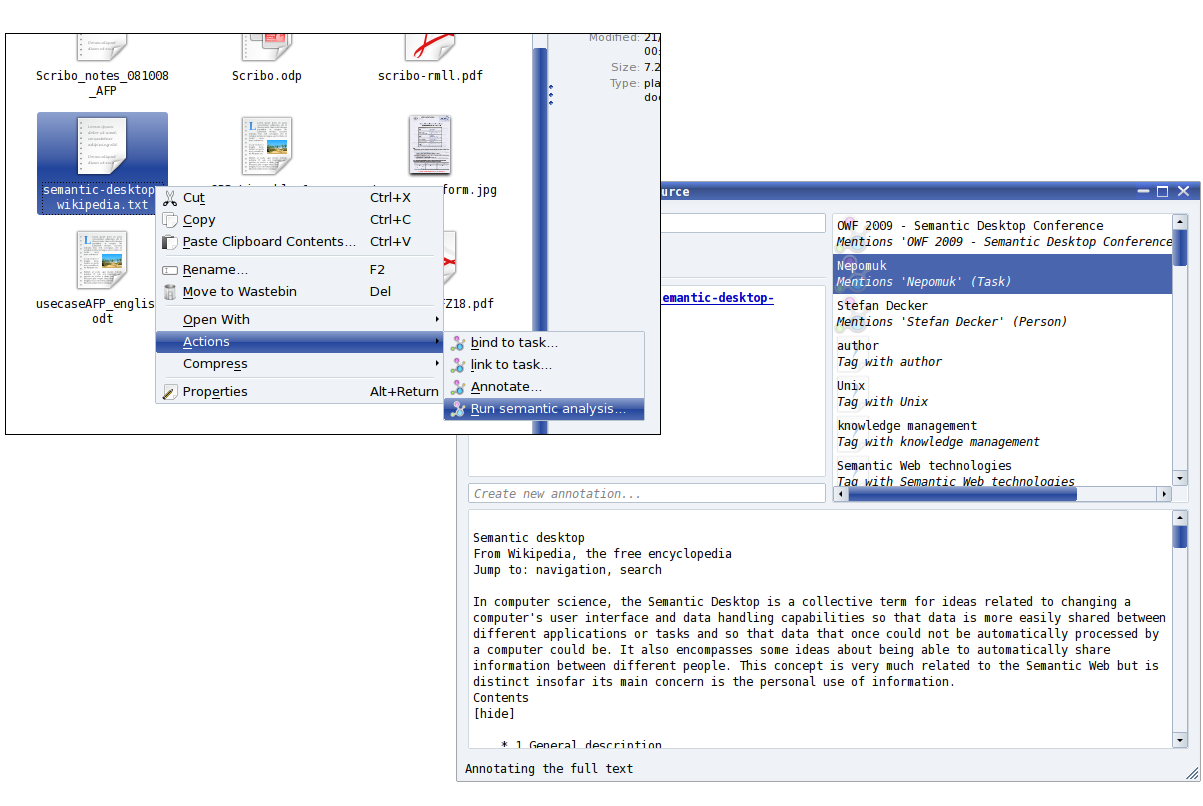
Scribo can analyze text files and suggest relationships via Nepomuk based on the words found. It can also recognize (using
Tesseract) text in images so that Nepomuk can suggest linking the image to items that are related to the identified text. These features can be tested in Mandriva Linux 2010 by right clicking on a text file, and selecting "Actions > Run semantic analysis". For an image it is "Actions > Annotate".
Future Scribo-based technologies
Scribo is designed to learn from the user interaction with the system, so that suggestions get better over time. Mandriva is teaming up with research organizations that have expertise in the natural language processing technologies. There are some far reaching possibilities such as
"routing technical queries to the appropriate documentation or discussion thread", using
Open Collaboration Services.
Summary
If you would like to check out some of the Nepomuk features present in Mandriva Linux 2010 then
their guide should get you up and running. Nepomuk is a whole new approach to managing information intelligently and the transformation of pure research into useful and robust tools obviously takes time. However, Nepomuk is already working behind the scenes in KDE software in ways you may have used without noticing and some advanced searching features are already available if you know how to use them. Stéphane, Sebastian and the wider KDE community will be working on integrating Nepomuk capabilities into applications in a more user-friendly and discoverable manner, now that the technological foundations are in place. A friendly Nepomuk based search interface is expected to debut with Dolphin in release 4.4 of the KDE Software Compilation and full browsing capabilities based on Nepomuk are aimed for inclusion in 4.5 in the form of faceted browsing. Wider integration of some of the other capabilities showcased in Mandriva Linux 2010 will follow.
Comments:
Looking forward to seeing - madman - 2009-12-10
Looking forward to seeing this pick up - keep it up! Wouldn't mind seeing something like KOffice's Krita fund for Nepomuk. That would be awesome. :D
Pledgie! - mutlu - 2009-12-10
I agree. I would be very willing to contribute some money if there was a pledge and if someone could be found to work on Nepomuk who might stick around as a volunteer contributor after that period of paid contributing.
In any case, I am very much looking forward to all future developments of this awesome project. Good luck!
This can be awesome... but... - Alejandro Nova - 2009-12-10
Greetings. It happens that I, a not so short time ago, switched to Adélie. And I found some minor (and not so minor) problems.
1. Is planned an update for libnepomukcontact4 and libnepomukpeopletag0 to 2010.0 (they require KDE 4.2 actually, so it's a little weird). Maybe this is solved by upgrading to PowerPack, but I don't know :P
2. KMail-Nepomuk is acceptable, but TaskTop freezes everything here, and it's unusable.
A revolution we might not even notice? - ArneBab - 2009-12-10
SCribo sounds like it can be a revolution (or at least a huge evolutionary step) in the way I use my computer - and it also sounds like one of the things which can become perfectly natural, so people only realize how much it offers once they have to use a system without it.
The only concern I have is that it might make my computer more pro-active but less reactive to the things I want it to do right now. It might become an interesting challenge for usability people.
How can you define an active interface which doesn't interfere with my workflow? Currently things like presenting actions via noninvasive icons comes to my mind (partly like the Zotero Firefox extension, but integrated into the whole system).
google summer of code - wintersommer - 2009-12-11
is coming :)
if oss dev needs money, not love :-)
Nepomuk is a nice tool for - kolla - 2009-12-12
Nepomuk is a nice tool for people who dont know how to organize their files and data in an orderly manner. Too bad those same people are also the ones most likely uncapable of annotating and using advanced search tools. And those of us who who already know how to organize our data and files in a strucured manner, dont need this tool. Nepotuk is one of many many things in KDE4 I really would want to opt out.
BTW Kolla, you are right. - Spaces - 2009-12-15
BTW Kolla, you are right. Nepomuk is useless and you are not the only one who likes to opt out.
Hmm - Stuart Jarvis - 2009-12-15
"those same people are also the ones most likely uncapable of annotating and using advanced search tools"
So that's why they aim to make tagging as automated as possible (and auto-indexing too, beyond tags) and the new, simpler search interfaces.
"those of us who who already know how to organize our data and files in a strucured manner, dont need this tool"
Perhaps. Do you access you music and images by arranging them in very neat carefully considered directories or do you use tools like Amarok and Digikam to organise them by metadata? I tend to see Nepomuk being useful for any situation where I have lots of files.
// Do you access you music - Spaces - 2009-12-16
// Do you access you music and images by arranging them in very neat carefully considered directories or do you use tools like Amarok and Digikam to organise them by metadata? //
Yes I do use folders. Folders (with meaningful name) is the best and fastest way to organize any type of documents (pictures etc). If you add meaningful file names, you got a system that is OS independent and you KNOW what is what and _where_ it is. No need no Nepofrak around with labels and what not. Do not forget, those labels you spent hours adding, will work only in your PC and only for you.
So, you tagged your pictures that are all over the HDD and you probably use file names that makes no sense to you or anyone else and you have folders like 'blah' and 'asd' in 10 different subfolders.
You relay on some silly tags, that can stop working any time and then you end up with what? Just a pile of files (probably all in the same folder too :)
Send a file out from your Digikam environment and you are fracked. You and everyone else have no idea what it is. asasasasd.JPG?
Only way to find out is is to open a file and say "ooh, this is my kids b-day blaa blaa blaa". What about hundreds of other files in folders "blah" and "asd"? What if you need to access your PC via ssh and copy some files you need to another location? Doh... no idea how to find them from this huge pile of socks and undies? Call mom? :)
I do not say that Digikam labels and "ratings" are totally useless. I use those occasionally for some specific task but if you have no solid underlying system to organize your folders and files you will be in trouble sooner or later.
PS! I work with hundreds of image files and documents every day. If I had to relay only on metadata I'll be in serous trouble. Thankfully we use file names and folders and guess what - it beats "metadata only" systems hands down.
Exactly right. - philrigby - 2009-12-16
Spaces, you're completely correct. I've been using file-and-directory based computers for 19 years, way way way before metadata existed so I've spent half my life knowing how to create directories and name files. I have no use for something such as nepomuk except for perhaps locating a file quicker than I can drill through the path to get there.
For example, my music is organised such:
~/Documents/Multimedia/Music/MP3s/Van Halen/ou812
Pretty easy to find the tracks off the ou812 album, no? Similarly, pictures of my kids from Halloween:
~/Documents/Multimedia/Graphics/Family/2009/2009-10-31
Nothing hard there about finding pictures.
I'm sure Nepomuk does have a very definite audience, but for people with some savvy about how to organise a hard drive, it is somewhat redundant.
"So that's why they aim to - kolla - 2009-12-18
"So that's why they aim to make tagging as automated as possible (and auto-indexing too, beyond tags) and the new, simpler search interfaces"
No doubt, and this is of absolutely no interest for people like me. On the contrary, auto-indexing etc. are just another annoyance, bogging down our systems. Imagine an office environment where people mount directories, perhaps even home directories, over network. Let's assume you have 100 such clients, all constantly auto-indexing files that are stored on network share, and maybe even storing the resulting index files also on network drives. Lots of fun, huh? In essence these "clever" things turns linux workstations into the exact same administrative nightmare that windows machines have been - and why? To atract appearantly rather ignorant windows users over.
"Do you access you music and images by arranging them in very neat carefully considered directories or do you use tools like Amarok and Digikam to organise them by metadata?"
I have my music stored in "artist/album/tracknr trackname" yes, always had. I also have some other random music files that I just keep in seperate folder, something that makes Amarok think I have close to hundred more albums than I do have, strange albums with typically just one or two tracks in them. I really just use the filebrowser tab in amarok to pick what to play, since the metadata index is filled with garbage I'll never bother to correct.
"I tend to see Nepomuk being useful for any situation where I have lots of files."
I have lots of files, and I still cant see it being of much use. And it's not just a tendency.
>> Nepomuk is a nice tool for - Jose_ - 2009-12-18
>> Nepomuk is a nice tool for people who dont know how to organize their files and data in an orderly manner. Too bad those same people are also the ones most likely uncapable of annotating and using advanced search tools. And those of us who who already know how to organize our data and files in a strucured manner, dont need this tool. Nepotuk is one of many many things in KDE4 I really would want to opt out.
What are you talking about?
Metadata is used all over the place.
Ever use a database where data had numerous associations with it?
Does the picture of aunt Tilda taken last year go into the pictures, family, friends, or 2008 folder/directory? Of course, you could repeat folder names as subfolders, and you can create folders with names like "Aunt Tilda pictures from last year", but the point is that files we save have lots of different ways to categorize them. Their is no single hierarchical ordering that is sufficient except through repetition like crazy.
The most accurate metadata tends to be the one you painstakingly contrive manually. You can benefit from Nepotuk.
Similarly, lots of applications will produce their own metadata automatically and this comes for free if you use Nepotuk. These can later be tweaked or extended.
A browser might save pages with the values you added to forms, with the http headers, with session info (including cookie info), with stats (eg, how long you had a page visible, how long open but hidden, how much up/down activity, etc). Perhaps you don't remember a page except that you arrived there via some news site (referrer) at an approximate date or where you had filled in certain information or saw a particular ad.
To take another example of the power of indexing based on metadata. The web is huge and every item has an url that does not follow any preset rules. Nevertheless, Google and other companies have huge indexes, scores, ... metadata to help identify needles in haystack if possible. Google, at least frequently, does an interesting job in many cases. Do you think web page authors are not adding keywords and all sorts of metadata to their pages in order to facilitate being found?
In fact, metadata, keywords, etc are things that might already exist in the data file itself but which can be especially highlighted and even given a special semantic meaning. This would allow for superior searching over simply scanning through every file or filesystem looking for words or phrases. Of course, some metadata does not exist in the file, eg, "nasty picture of X, by the lake Y, taken by my hyper friend Z, converted to a png, placed inside a pdf, later emailed to the pic contest...."
Another very important use for metadata is to tag software projects (and lines of source code in general) and any item within any type of project, really, as a way to help facilitate the automation of finding, building, interfacing, (re)starting, (re)configuring, controlling, etc, software based on user needs instead of based on the needs of a central distro maintainer. This would work alongside a standardization of tags. As a simple example of a query (though querying is not the most interesting thing to be done), imagine getting a list of all the files that are licensed a particular way (FOSS, or GPL, or belonging to author X, etc). This would be enabled through extensive tagging using standard tags and then having the central system (Nepomuk or similar) index appropriately. Once most pieces of work you find online use standard tags, this can all be gotten for free, more or less. Surely there will be central repos of tag files (think xml) associated with well-named items on the Internet. In fact, maybe we are leading up to WikiTag.org or something similar (Opensearch.org, opendirectory, etc). Even runtime configuration can lead to tags. Capabilities can become tags. Requirements of all sorts can become tags. Versions and source/document/etc urls can become tags. [BTW, the tags can be related to each other.. think of element tags in an xml file.]
I'm likely to think a person downplaying the potential of Nepomuk and related efforts is but a competitor wanting this project to fail or be left unnurtured so they can get ahead of it.
You are missing the point. - Spaces - 2009-12-26
You are missing the point. Point is this: people, who can not even organize files in to a folders or use file names, that make sense after 2 days, will not tag pictures (non text files) with meaningful tags nor will they add meaningful metadata because it is even more time consuming (read: boring).
Extracting camera metadata form images (EXIF, TIFF) is useless to most soap box camera Joe's out there.
Do you really think that something like IPTC data for images just appears automagically? Hell no! Is it useful? Hell yeah! But someone with pulse must write it first. :)