Robert Kaye -- Music Buff, Entrepreneur, Akademy Keynote Speaker

Robert Kaye is definitely a brainz-over-brawn kinda guy. As the creator of MusicBrainz, ListenBrainz and AcousticBrainz, all created and maintained under the MetaBrainz Foundation, he has pushed Free Software music cataloguing-tagging-classifying to the point it has more or less obliterated all the proprietary options.
In July he will be in Almería, delivering a keynote at the 2017 Akademy -- the yearly event of the KDE community. He kindly took some time out of packing for a quick trip to Thailand to talk with us about his *Brainz projects, how to combine altruism with filthy lucre, and a cake he once sent to Amazon.
Robert Kaye: Hola, ¿qué tal?
Paul Brown: Hey! I got you!
Robert: Indeed. :)
Paul: Are you busy?
Robert: I'm good enough, packing can wait. :)
Paul: I'll try and be quick.
Robert: No worries.
* Robert has vino in hand.
Paul: So you're going to be delivering the keynote at Akademy...
* Robert is honored.
Paul: Are you excited too? Have you ever done an Akademy keynote?
Robert: Somewhat. I've got... three? Four trips before going to Almería. :)
Paul: God!

Robert: I've never done a keynote before. But I've done tons and tons of presentations and speeches, including to the EU, so this isn't something I'm going to get worked up about thankfully.
Paul: I'm assuming you will be talking about MetaBrainz. Can you give us a quick summary of what MetaBrainz is and what you do there?
Robert: Yes, OK. In 1997/8 in response to the CDDB database being taken private, I started the CD Index. You can see a copy of it in the Wayback Machine. It was a service to look up CDs and I had zero clues about how to do open source. Alan Cox showed up and told me that databases would never scale and that I should use DNS to do a CD lookup service. LOL. It was a mess of my own making and I kinda walked away from it until the .com crash.
Then in 2000, I sold my Honda roadster and decided to create MusicBrainz. MusicBrainz is effectively a music encyclopedia. We know what artists exist, what they've released, when, where their Twitter profiles are, etc. We know track listings, acoustic fingerprints, CD IDs and tons more. In 2004 I finally figured out a business model for this and created the MetaBrainz Foundation, a California tax-exempt non-profit. It cannot be sold, to prevent another CDDB. For many years MusicBrainz was the only project. Then we added the Cover Art Archive to collect music cover art. This is a joint project with the Internet Archive.
Then we added CritiqueBrainz, a place for people to write CC licensed music reviews. Unlike Wikipedia, ours are non-neutral POV reviews. It is okay for you to diss an album or a band, or to praise it.
Paul: An opinionated musical Wikipedia. I already like it.
Robert: Then we created AcousticBrainz, which is a machine learning/analysis system for figuring out what music sounds like. Then the community started BookBrainz. And two years ago we started ListenBrainz, which is an open source version of last.fm's audioscrobbler.
Paul: Wait, let's backtrack a second. Can you explain AcousticBrainz a bit more? What do you mean when you say "figure out what music sounds like"?
Robert: AcousticBrainz allows users to download a client to run on their local music collection. For each track it does a very detailed low-level analysis of the acoustics of the file. This result is uploaded to the server and the server then does machine learning on it to guess: Does it have vocals? Male of female? Beats per minute? Genre? All sorts of things and a lot of them need a lot of improvement still.
Paul: Fascinating.
Robert: Researchers provided all of the algorithms, being very proud and all: "I've done X papers on this and it is the state of the art". State of the art if you have 1,000 audio tracks, which is f**king useless to an open source person. We have three million tracks and we're not anywhere near critical mass. So, we're having to fix the work the researchers have done and then recalculate everything. We knew this would happen, so we engineered for it. We'll get it right before too long.
All of our projects are long-games. Start a project now and in five years it might be useful to someone. Emphasis on "might".
Then we have ListenBrainz. It collects the listening history of users. User X listened to track Y at time Z. This expresses the musical taste of one user. And with that we have all three elements that we've been seeking for over a decade: metadata (MusicBrainz), acoustic info (AcousticBrainz) and user profiles (ListenBrainz). The holy trinity as it were. You need all three in order to build a music recommendation engine.
The algorithms are not that hard. Having the underlying data is freakishly hard, unless you have piles of cash. Those piles of cash and therefore the engines exist at Google, Last.fm, Pandora, Spotify, et al. But not in open source.
Paul: Don't you have piles of cash?
Robert: Nope, no piles of cash. Piles of eager people, however! So, once we have these databases at maturity we'll create some recommendation engine. It will be bad. But then people will improve it and eventually a pile of engines will come from it. This has a significant chance of impacting the music world.
Paul: You say that many of the things may be useful one day, but you also said MetaBrainz has a business model. What is it?
Robert: The MetaBrainz business model started out with licensing data using the non-commercial licenses. Based on "people pay for frequent and easy updates to the data". That worked to get us to 250k/year.
Paul: Licensing the data to...?
Robert: The MusicBrainz core data. But there were a lot of people who didn't need the data on an hourly basis.
Paul: Sorry. I mean who were you licensing to?
Robert: It started with the BBC and Google. Today we have all these supporters. Nearly all the large players in the field use our data nowadays. Or lie about using our data. :)
Paul: Lie?
Robert: I've spoken to loads of IT people at the major labels. They all use our data. If you speak to the execs, they will swear that they have never used our data.
Paul: Ah. Hah hah. Sounds about right.
Robert:Anyways, two years ago we moved to a supporter model. You may legally use our data for free, but morally you should financially support us. This works.
Paul: Really?
Robert: We've always used what I call a "drug dealer business model". The data is free. Engineers download it and start using it. When they find it works and want to push it into a product they may do that without talking to us. Eventually we find them and knock on their door and ask for money.
Paul: They pay you? And I thought the music industry was evil.
Robert: This is the music tech companies. They know better.
Anyways...
Their bizdev types will ask: where else can we get this data for cheaper? The engineers look around for other options. Prices can range from 3x to 100x, depending on use, and the data is not nearly as good. So they sign up with us. This is not out of the kindness of their hearts.
Paul: Makes more sense now.
Robert: Have you heard the Amazon cake story?
Paul: The what now?
Robert: Amazon was 3 years behind in paying us. I harangued them for months. Then I said: "If you don't pay in 2 weeks, I am going to send you a cake."
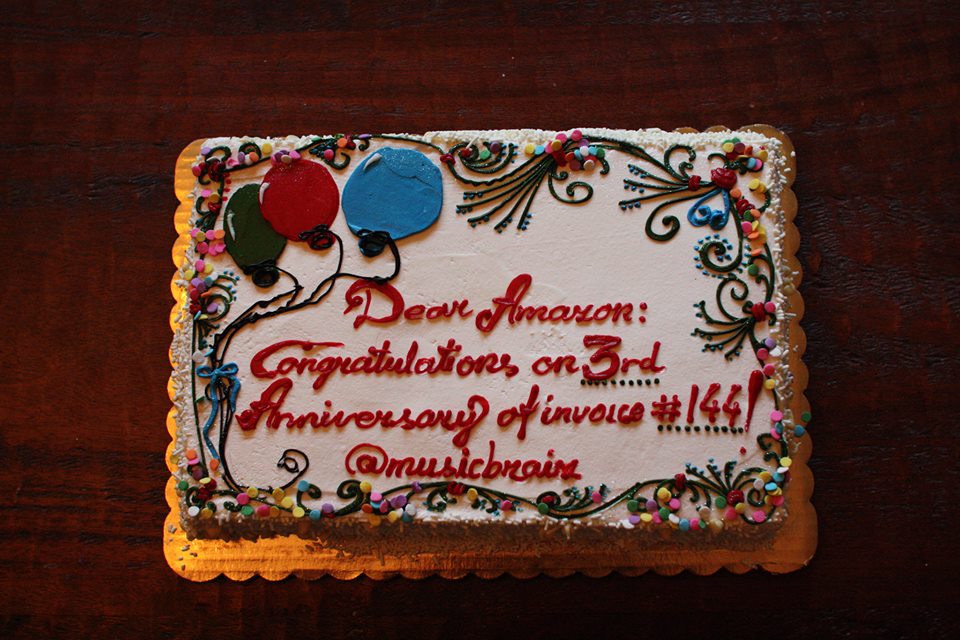
"A cake?"
"Yes, a cake. One that says 'Congratulations on the 3rd anniversary'..."
They panicked, but couldn't make it happen.
So I sent the cake, then silence for 3 days.
Then I got a call. Head of legal, head of music, head of AP, head of custodial, head of your momma. All in one room to talk to me. They rattled off what they owed us. It was correct. They sent a check.
Cake was sent on Tuesday, check in hand on Friday.
This was pivotal for me: recognizing that we can shame companies to do the right thing... Such as paying us because to switch off our data (drugs) is far worse than paying.
Last year we made $323k, and this year should be much better. We have open finances and everything. People can track where money goes. We get very few questions about us being evil and such.
Paul: How many people work with you at MetaBrainz, as in, are on the payroll?
Robert: This is my team. We have about 6 full-time equivalent positions. To add to that, we have a core of contributors: coders, docs, bugs, devops... Then a medium ring of hard-core editors. Nicolás Tamargo and one other guy have made over 1,000,000 edits to the database!
Paul: How many regular volunteers then?
Robert: 20k editors per year. Más o menos. And we have zero idea how many users. We literally cannot estimate it. 40M requests to our API per day. 400 replicated copies of our DB. VLC uses us and has the largest installation of MusicBrainz outside of MetaBrainz.
And we ship a virtual machine with all of MusicBrainz in it. People download that and hammer it with their personal queries. Google Assistant uses it, Alexa might as well, not sure. So, if you ask Google Assistant a music-related question, it is answered in part by our data. We've quietly become the music data backbone of the Internet and yet few people know about us.
Paul: Don't you get lawyers calling you up saying you are infringing on someone's IP?
Robert: Kinda. There are two types: 1) the spammers have found us and are hammering us with links to pirated content. We're working on fixing that. 2) Other lawyers will tell us to take content down, when we have ZERO content. They start being all arrogant. Some won't buzz off until I tell them to provide me with an actual link to illegal content on our site. And when they can't do it, they quietly go away.
The basic fact is this: we have the library card catalog, but not the library. We mostly only collect facts and facts are not copyrightable.
Paul: What about the covers?
Robert: That is where it gets tricky. We engineered it so that the covers never hit our servers and only go to the Internet Archive. The Archive is a library and therefore has certain protections. If someone objects to us having something, the archive takes it down.
Paul: Have you had many objections?
Robert: Not that many. Mostly for liner notes, not so much for covers. The rights for covers were never aggregated. If someone says they have rights for a collection, they are lying to you. It's a legal mess, plain and simple. All of our data is available under clear licenses, except for the CAA -- "as is"
Paul: What do you mean by "rights for a collection"?
Robert: Rights for a collection of cover art. The rights reside with the band. Or the friend of the band who designed the cover. Lawyers never saw any value in covers pre-Internet. So the recording deals never included the rights to the covers. Everyone uses them without permission
Paul: I find that really surprising. So many iconic covers.
Robert: It is obvious in the Internet age, less so before the Internet. The music industry is still quite uncomfortable with the net.
Paul: Record labels always so foresightful.
Robert: Exactly. Let's move away from labels and the industry.
Though, one thing tangentially, I envisioned X, Y, Z, uses for our data, but we made the data rigorous, well-connected and concise. Good database practices. And that is paying off in spades. The people who did not do that are finding that their data is no longer up to snuff for things like Google Assistant.
Paul: FWIW, I had never heard of Gracenote until today. I had heard of MusicBrainz, though. A lot.
Robert: Woo! I guess we're succeeding. :)
Paul: Well, it is everywhere, right?
Robert: For a while it was even in Antarctica! A sysadmin down there was wondering where the precious bandwidth went during the winter. Everyone was tagging their music collection when bored. So he set up a replica for the winter to save on bandwidth.
Paul: Of course they were and of course he did.
Robert: Follows, right? :)
Paul: Apart from music, which you clearly care for A LOT, I heard you are an avid maker too.
Robert: Yes. Party Robotics was a company I founded when I was still in California and we made the first affordable cocktail robots. But I also make blinky LED light installations. Right now I am working on a sleep debugger to try and improve my crapstastic sleep.
I have a home maker space with an X-Carve, 3D printer, hardware soldering station and piles of parts and tools.
Paul: Uh... How do flashing lights help with sleep?
Robert: Pretty lights and sleep-debugging are separate projects.
Paul: What's your platform of choice, Arduino?
Robert: Arduino and increasingly Raspberry Pi. The Zero W is the holy grail, as far as I am concerned.
Oh! And another project I want: ElectronicsBrainz.
Paul: This sounds fun already. Please tell.
Robert: Info, schematics and footprints for electronic parts. The core libraries with KiCad are never enough. you need to hunt for them. Screw that. Upload to ElectronicBrainz, then, if you use a part, rate it, improve it. The good parts float to the top, the bad ones drop out. Integrate with Kicad and, bam! Makers can be much more useful. In fact, this open data paradigm and the associated business model is ripe for the world. There are data silos everywhere.
Paul: I guess that once you have set up something like MusicBrainz, you start seeing all sorts of applications in other fields.
Robert: Yes. Still, we can't do everything. The world will need more MetaBrainzies.
Paul: Meanwhile, how can non-techies help with all these projects?
Robert: Editing data/adding data, writing docs or managing bug reports as well. Clearly our base of editors is huge. It is a very transient community, except for the core.
Also, one thing that I want to mention in my keynote is blending volunteers and paid staff. We've been really lucky with that. The main reason for that is that we're open. We have nothing to hide. We're all working towards the same goals: making the projects better. And when you make a site that has 40M requests in a day, there are tasks that no one wants to do. They are not fun. Our paid staff work on all of those.
Volunteers do the things that are fun and can transition into paid staff -- that is how all of our paid staff became staff.
Paul: This is really an incredible project.
Robert: Thanks! Dogged determination for 17 years. It’s worth something.
Paul: I look forward to your keynote. Thank you for your time.
Robert: No problem.
Paul: I'll let you get back to your packing.
Robert: See you in Almería.
Robert Kaye will deliver the opening keynote at Akademy 2017 on the 22nd of July. If you would like to see him and talk to him live, register here.
About Akademy
For most of the year, KDE—one of the largest free and open software communities in the world—works on-line by email, IRC, forums and mailing lists. Akademy provides all KDE contributors the opportunity to meet in person to foster social bonds, work on concrete technology issues, consider new ideas, and reinforce the innovative, dynamic culture of KDE. Akademy brings together artists, designers, developers, translators, users, writers, sponsors and many other types of KDE contributors to celebrate the achievements of the past year and help determine the direction for the next year. Hands-on sessions offer the opportunity for intense work bringing those plans to reality. The KDE Community welcomes companies building on KDE technology, and those that are looking for opportunities. Join us by registering for the 2017 edition of Akademy today.
For more information, please contact the Akademy Team.