Planet KDE

Ruqola 2.3.1
Ruqola 2.3.1 is a feature and bugfix release of the Rocket.chat app.
New features:
- Use "view-conversation-balloon-symbolic" icon when we have private conversation with multi users
- Add version in market application information
- Fix reset password
- Fix mouse position when QT_SCREEN_SCALE_FACTORS != 1
- Add missing icons
- Fix create topic when creating teams
- Fix discussion count information
- Remove @ or # when we search user/channel
- Fix edit message logic
URL: https://download.kde.org/stable/ruqola/
Source: ruqola-2.3.1.tar.xz
SHA256: 99356ec689473cd5bfaca7f8db79ed5978efa8b3427577ba7b35c1b3714d5fcb
Signed by: E0A3EB202F8E57528E13E72FD7574483BB57B18D Jonathan Riddell [email protected]
https://jriddell.org/jriddell.pgp
Warning: Krita 5.2.6 beta on Android is currently broken
On releasing the latest version of Krita in our Android/ChromeOS beta program, we discovered, too, late that there was a problem that could prevent Krita from starting.
Since the Google Play Store Console does not allow revering a release to an earlier version, we are now urgently working on a fix which we will release as soon as possible.
Our apologies for the inconvience.
The currentl nightly builds for Android work again, with some limitations:
- take care removing the store version of Krita does not remove the application data: your artwork could be lost.
- in the Nightly builds you need to install any brush presets separately
You can get the night builds here: Krita Next Nightly Builds. You will need to select the package that is right for the architecture of your device.
Installing the nightly builds requires enabling developer mode on your device and needs considerable technical insight.
If you do not feel comfortable with this, please wait until the new official release lands in the play store in a about two days.
PSA: KDecoration API break in Plasma 6.3
Fractional scaling is hard. Anyone that had the misfortune of working on it knows that… so it won’t surprise a lot of people that it’s not all figured out yet! Today I’ll talk about the fractional scaling problems with KWin’s server side decorations, and why we need to do an API break to fix it.
What’s the problem?This is the simplest part. Many decorations have elements that need to be pixel perfect, like outlines that are only a single pixel wide. When they’re not perfectly scaled, or positioned wrongly, that’s sometimes quite visible and annoying:



The source of all evil with fractional scaling is also the cause of most issues here: Integer logical coordinates.
Logical coordinates are a way to represent the size of something on the screen in a mostly display-independent way and are quite useful for the size and position of things like windows or the cursor. They’re calculated in a really simple way:
With just that equation, there are no problems just yet - you can just multiply the logical coordinate with the display scale, and you get back the original coordinate in pixels. When you round that logical coordinate, and do some calculations with it, things get weird though… let’s look at the concrete example of a window at scale 1.25, and with a 1 pixel wide outline:
unit outline width window width outline width total size total size in pixels (integer) pixels 1 27 1 29 29 fractional logical 0.8 21.6 0.8 23.2 29 integer logical 1 22 1 24 30As you might’ve guessed, KWin’s decoration plugin API is using integer logical coordinates, and this mismatch between the window size vs. the size of its components causes most of the problems. Just doing a straight forward int -> float conversion isn’t enough to fix this though, a few more changes are needed.
Changes in KWinKWin will provide decorations with the fractional logical size of windows, provide them with the scale factor they should render for, and use the decoration’s fractional border sizes to position the window and decoration pieces properly in the scene.
Changes in DecorationsBecause of the API break, decorations using the C++ API need to be updated to the new KDecoration3 API, or they will not be loaded. A minimalistic port would only need to round all the values, but there will of course still be fractional scaling issues with that.
Assuming you want to make the decoration work properly with fractional scaling, you also need to use the provided scale factor to calculate border sizes, and when painting things with QPainter, you need to take care to snap all geometries to the pixel grid, or anti-aliasing may turn single-pixel lines into a blurry mess.
Note that this work isn’t completed yet, and some additional API changes may happen while we’re breaking the API already. A porting guide with all the changes will be provided before the release of Plasma 6.3.
As Aurorae decorations are just svg files, they are not affected by this API break and will continue to work like before without any changes.
If you have any questions about this change, or about how to port a decoration over to the new API, please reach out to us at #kwin:kde.org on matrix!
Improving Xwayland window resizing
One of the quickest ways to determine whether particular application runs using Xwayland is to resize one of its windows and see how it behaves, for example
While it can be handy for the debugging purposes, overall, it makes the Plasma Wayland session look less polished. So, one of the goals for 6.3 was to fix this visual glitch.
This article will provide some background behind what caused the glitch and how we addressed it. Just in case, here’s the same application, which was shown in a screen cast above, but with the corresponding resizing fixes in:
X11 frame synchronization protocol(s)On X11, all window changes typically take place immediately, including resizing. This can lead to some issues. For example, if a window is resized, it can take a while until the application repaints the window with the new size. What if the compositing manager decides to compose the screen in meanwhile? You’re likely going to see some sort of visual glitches, e.g. the window contents getting cropped or seeing parts of the window that have not been repainted yet.
In order to address this issue, there exists an X11 protocol to synchronize window repaints during interactive resize. An application/client wishing to participate in this protocol needs to list _NET_WM_SYNC_REQUEST in the WM_PROTOCOLS property of the client window and also set the XID of the XSync counter in the _NET_WM_SYNC_REQUEST_COUNTER property. When the WM wants to resize the window, the following will happen:

- The window manager sends a _NET_WM_SYNC_REQUEST client message containing a serial that the client will need to put in the XSync counter after processing a ConfigureNotify event that will be generated after the window is resized. The compositing manager and the window manager will block window updates until the XSync request acknowledgement is received;
- The WM resizes the client window, for example by calling the xcb_configure_window() function;
- The client would then repaint the window with the new size and update the XSync counter with the serial that it had received in step 1;
- The window manager and the compositing manager unblock window updates after receiving receiving the XSync request acknowledgement. For example, now, the window can be repainted by the compositing manager and there shouldn’t be glitches as long as the client behaves well.
Note that the window manager and the compositing manager are often the same. For example, both KWin and Mutter are compositing managers and window managers.
The frame synchronization protocol described above is called basic frame synchronization protocol. There is also an extended frame synchronization protocol, but it is not standardized and it is implemented only by a few compositing managers.
_NET_WM_SYNC_REQUEST and XwaylandKWin supports the basic frame synchronization protocol, so there should be no visual glitches when resizing X11 windows in the Plasma Wayland session, right? At quick glance, yes, but we forget about the most important detail: Wayland compositors don’t use XCompositeNameWindowPixmap() or xcb_composite_name_window_pixmap() to grab the contents of X11 windows, instead they rely on Xwayland attaching graphics buffers to wl_surface objects, so there is no strict order between the Wayland compositor receiving an XSync request acknowledgement and graphics buffers for the new window size.
In order to help better understand the issue, let’s consider a concrete example. Assume that a window with geometry 0,0 100x100 is being resized by dragging its left edge. If the left edge is dragged 10px to the right, the following will happen:
- A _NET_WM_SYNC_REQUEST client message will be sent to the client containing the XSync counter serial that must be set after processing the ConfigureNotify event that will be generated after the Wayland compositor calls xcb_configure_window() with the new window size;
- The Wayland compositor calls xcb_configure_window() to actually resize the window;
- The client receives the sync request client message and the ConfigureNotify event, repaints the window, and acknowledges the sync request;
- The Wayland compositor receives the sync request acknowledgement and updates the window position to 10,0.
But here is the problem, when the window position is updated to 10,0, it’s not guaranteed that the wl_surface associated with the X11 window has a buffer with the new window size, i.e. 90x100. It can take a while until Xwayland commits a graphics buffer with the right size. In meanwhile, the compositor could compose the next frame with the new window position, i.e. 10,0, but old surface size, i.e. 100x100. It would look as if the right window edge sticks out of the window decoration. After Xwayland attaches a buffer with the right size, the right window edge will correct itself.
So, ideally, the Wayland compositor should update the window position after receiving the XSync request acknowledgement and Xwayland attaching a new graphics buffer to the wl_surface.
With that in mind, the frame synchronization procedure looks as follows:

- The compositor blocks wl_surface commits by setting the _XWAYLAND_ALLOW_COMMITS property to 0 for the toplevel X11 window. This is needed to ensure the consistent order between XSync request acknowledgements and wl_surface commits. As long as the _XWAYLAND_ALLOW_COMMITS property is set to 0, Xwayland will not attempt to commit the wayland surface, for example attach a new graphics buffer after the client repaints the window;
- The compositor sends a _NET_WM_SYNC_REQUEST client message as before;
- The compositor resizes the client window as before;
- The client repaints the window and acknowledges the XSync request as before;
- After receiving the XSync acknowledgement, the compositor unblocks surface commits by setting the _XWAYLAND_ALLOW_COMMITS property to 1. Note that the window updates are still blocked, i.e. the window position is not updated yet;
- After Xwayland commits the wl_surface with a new graphics buffer, the window updates are unblocked, e.g. the window position is updated.
The frame synchronization process looks more involved with Xwayland, but it is still manageable.
_NET_WM_SYNC_REQUEST support in applicationsMost applications that use GTK and Qt support _NET_WM_SYNC_REQUEST, but there are applications that don’t participate in the frame synchronization protocol. If you use one of those apps, you will observe visual glitches during interactive resize.
Closing wordsFrame synchronization is a difficult problem, and requires some very intricate code both on the compositor and the client side. But with the changes that we’ve made, I’m proud to say that KWin is one of the few compositors that properly handles frame synchronization for X11 windows on Wayland.
I would also like to express many thanks to the Xwayland developers (Michel Dänzer and Olivier Fourdan) for helping and assisting us with fixing the glitch.
Kwave Update - October 2024
Kwave is an audio editor based on the KDE Frameworks. It was started in 1998 by Martin Wilz, and Thomas Eschenbacher has been the main developer since 1999. In recent years development has slowed. I wanted to do some software development and contribute to KDE, and I’m interested in audio, so towards the end of 2023 I started working on Kwave.
Kwave had not been ported to Qt 6 and KDE Frameworks 6 yet, so that’s what I started working towards. My first merge requests were to update deprecated code. (MR Convert plugin desktop files to json, MR Port away from deprecated Qt API, MR port away from deprecated I18N_NOOP macros, MR bump KF5_MIN_VERSION and update where KMessageBox API has been deprecated, MR port QRegExp to QRegularExpression)
With that preparatory work done, I worked at porting Kwave to Qt 6 and KDE Frameworks 6. Most of that work was straight-forward. The biggest changes were in Qt Multimedia, which Kwave can use for playback and recording. I finally got that done and merged in August 2024, just after version 24.08 was branched, so that change will get released in version 24.12 in December 2024. (MR port to Qt6 and KF6)
Next I did some code cleanup. (MR use ECMGenerateExportHeader, MR add braces to avoid ambiguous else, MR call KCrash::initialize() after KAboutData::setApplicationData())
Laurent Montel added the FreeBSD job to the Continuous Integration configuration, but the build failed initially. I’ve never ran FreeBSD, but with a few tries and pushing changes to trigger CI, I managed to get the CI to pass. I’m glad Laurent took the initiative here, because the FreeBSD job uses clang, so with the existing Linux job using gcc, CI makes sure Kwave builds with both compilers now. (MR Add freebsd)
I applied for a KDE Developer account and got approved on August 24, 2024. Now I could commit changes myself instead of having to remind others to do it.
Carl Schwan cleaned up some code and updated the zoom toolbar to use standard icons, which enabled removing the built-in zoom icons. (MR Modernize ZoomToolbar) That was the incentive I needed to remove the rest of the built-in icons and use standard icons instead, which helps Kwave fit the users theme better. (MR use icons from current theme) I also reordered the playback toolbar in a way that seemed more logical to me. (MR update player toolbar)
I investigated a bug: Kwave Playback settings dialog loads incorrectly until you switch playback methods and fixed it in MR: make sure a valid method gets selected when PlayBackDialog opens
I have some more work in progress, and I plan to continue working on Kwave. I will try to blog about what I’m doing, but I’m not going to commit to any regular schedule.
Get InvolvedKwave depends on the rest of KDE. It is built on the Frameworks, and the KDE sysadmin team keeps the infrastructure running. You can help KDE by getting involved, or at least donate.
If you would like to help improve Kwave, use it and try out its features! If you have questions or ideas, discuss them. If you find bugs, report them. If you want to get involved with development, download the source code and start hacking!
If you think my own work on Kwave is worth something and you can afford it, you can donate to me through Liberapay, Stripe, or PayPal.
Linux App Summit 2024
As we have been doing yearly, a few weeks ago we had the 2024 edition of Linux App Summit (LAS). For those of you who don’t know, the Linux App Summit is a conference co-organised between KDE and GNOME among others where to bring together the different stakeholders of the linux ecosystem to make sure we have all the collaboration tools in place to have a great state of the art platform for the uses the world needs from us.

This year it was special in that since it became the Linux App Summit, we held it outside of Europe! We had LAS in Monterrey, the northernmost part of México in the ITESM (Instituto Tecnológico y de Estudios Superiores de Monterrey), a really nice campus and a beautiful venue.
Besides meeting people from other projects as I’d normally do in LAS, this year I had the added opportunity to meet the community the other side of the ocean. There certainly are good differences between how we organise FOSS communities Europe and there, it’s always useful to experience and iterate to ensure we are truly creating a community for everyone.
LAS ’25, Call for hostsAre you considering bringing such communities to your home town? Please reach out, you can find some information how to do that here: https://linuxappsummit.org/bids/.
In my opinion, organising a conference is one of the best ways to bring FOSS talent to where you are. It’s often hard to find new ways to be part of what we do, this is a great one. I personally had the opportunity to do it in LAS’19 in Barcelona and it was a great experience.
LAS has the added value of being a melting pot of people from different communities so it’s a great opportunity to meet people that you might not crossed paths with before!

This Week in KDE Apps
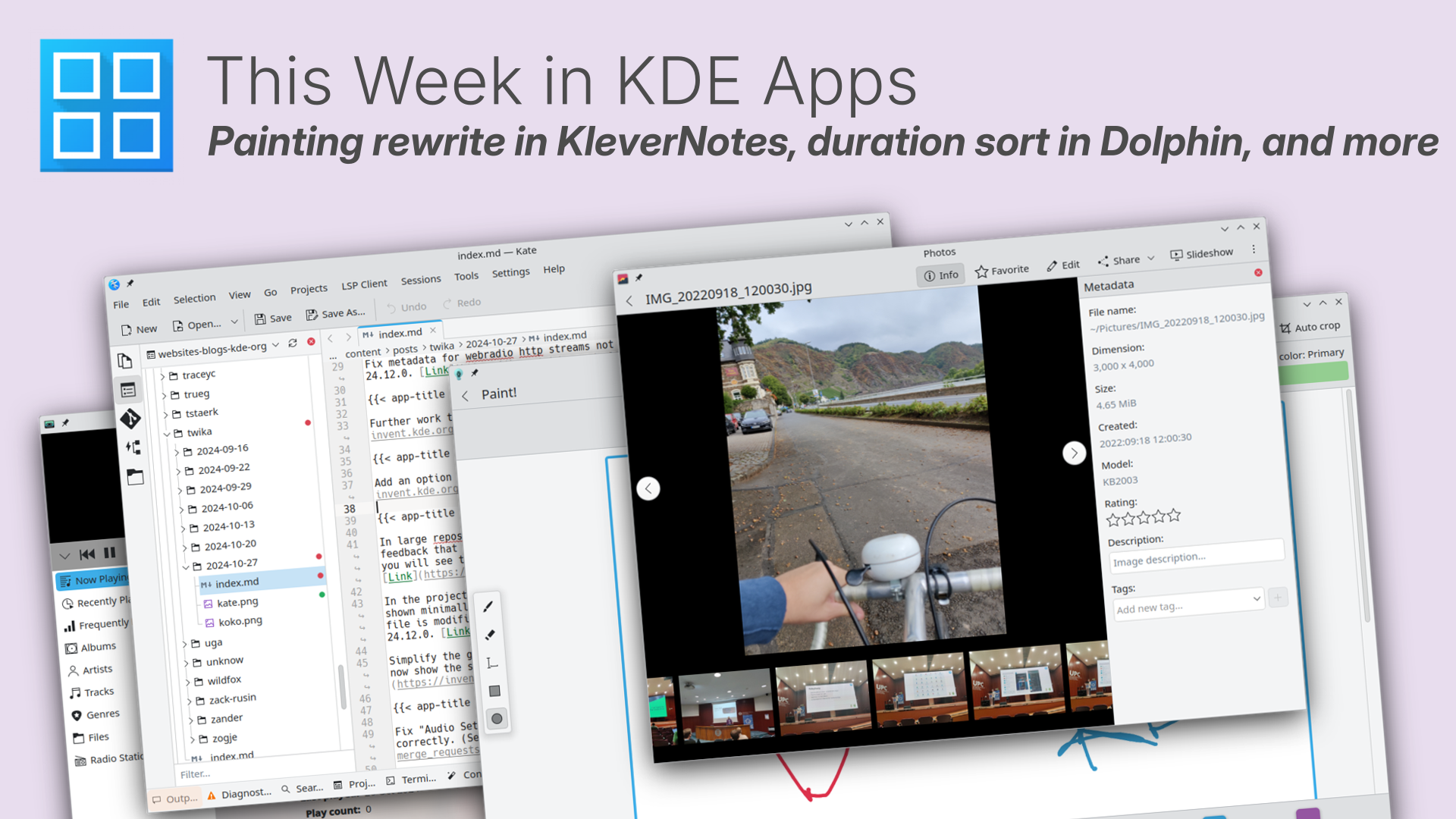
Welcome to a new issue of "This Week in KDE Apps"! Every week we cover as much as possible of what's happening in the world of KDE apps.
This week's changes and improvements cover a wide range of applications, from audio apps (including the classic Amarok, which is making a comeback) to Kate getting improvements to its integrated Git features.
In between, you have everything from new functionalities for note-taking utilities and media players, to upgrades in financial software and mobile apps.
Let's dig in!
Amarok A powerful music player that lets you rediscover your musicTuomas Nurmi worked on making the codebase Qt6-compatible. (Tuomas Nurmi, Link)
Ark Archiving ToolJin Liu disabled the "Compress to tar.gz/zip" service menu items in read-only directories. (Jin Liu, 24.12.0. Link)
Dolphin Manage your filesYou can now sort your videos by duration. (Somsubhra Bairi, 24.12.0. Link)
Eren Karakas added more standard actions (Sort By, View Mode, Cut and Copy) to the context menu in the trash view. (Eren Karakas, 24.12.0. Link)
Elisa Play music and listen to online radio stationsElisa now supports loading lyrics from .lrc files sitting alongside the song files. (Gary Wang, 24.12.0. Link)
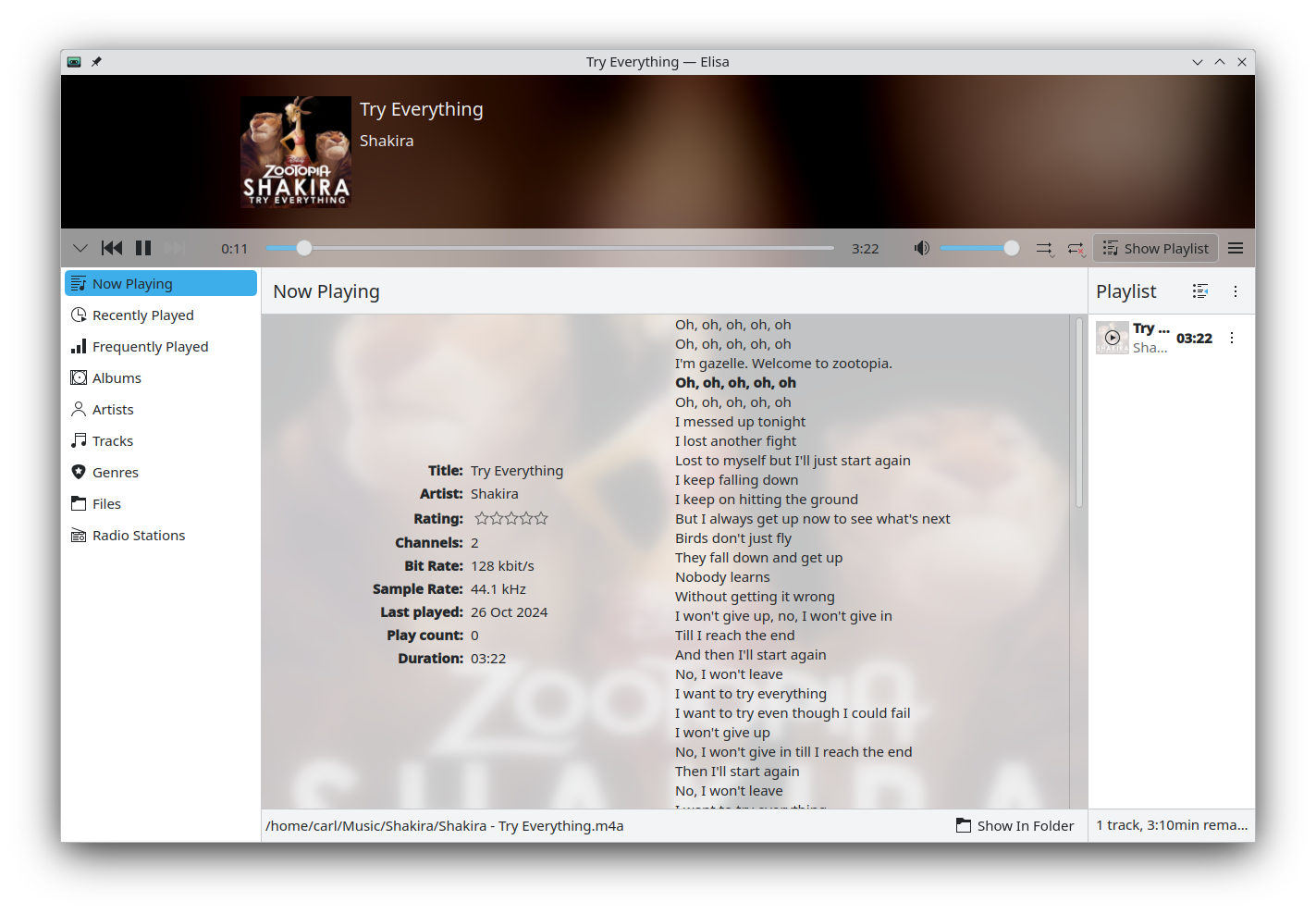
Manuel Roth fixed the bug in which the metadata for webradio http streams was not getting displayed. (Manuel Roth, 24.12.0. Link)
Haruna Media playerYou now have the option to open videos in full screen mode. (Rikesh Patel, Link)
KDE Itinerary Digital travel assistantVolker Krause was at the OSM Hack Weekend last week and worked on the support of MOTIS v2 API support in the public transport client library used by KDE Itinerary. He also added a map view of an entire trip to Itinerary and the KPublicTransport demo application.
Kate Advanced Text EditorIn large repos, a git status update can be slow. The least we can do for the user is show that something is happening. Hence, now, if the git status is being refreshed you will see the refresh button become unclickable and start spinning. (Waqar Ahmed, 24.12.0. Link)
In the project tree view, files will now show their status in git. The status is shown minimally, i.e. via a small circle displayed in front of the file name. If the file has been modified, the circle is red; if the file is staged, it's green. (Waqar Ahmed, 24.12.0. Link)
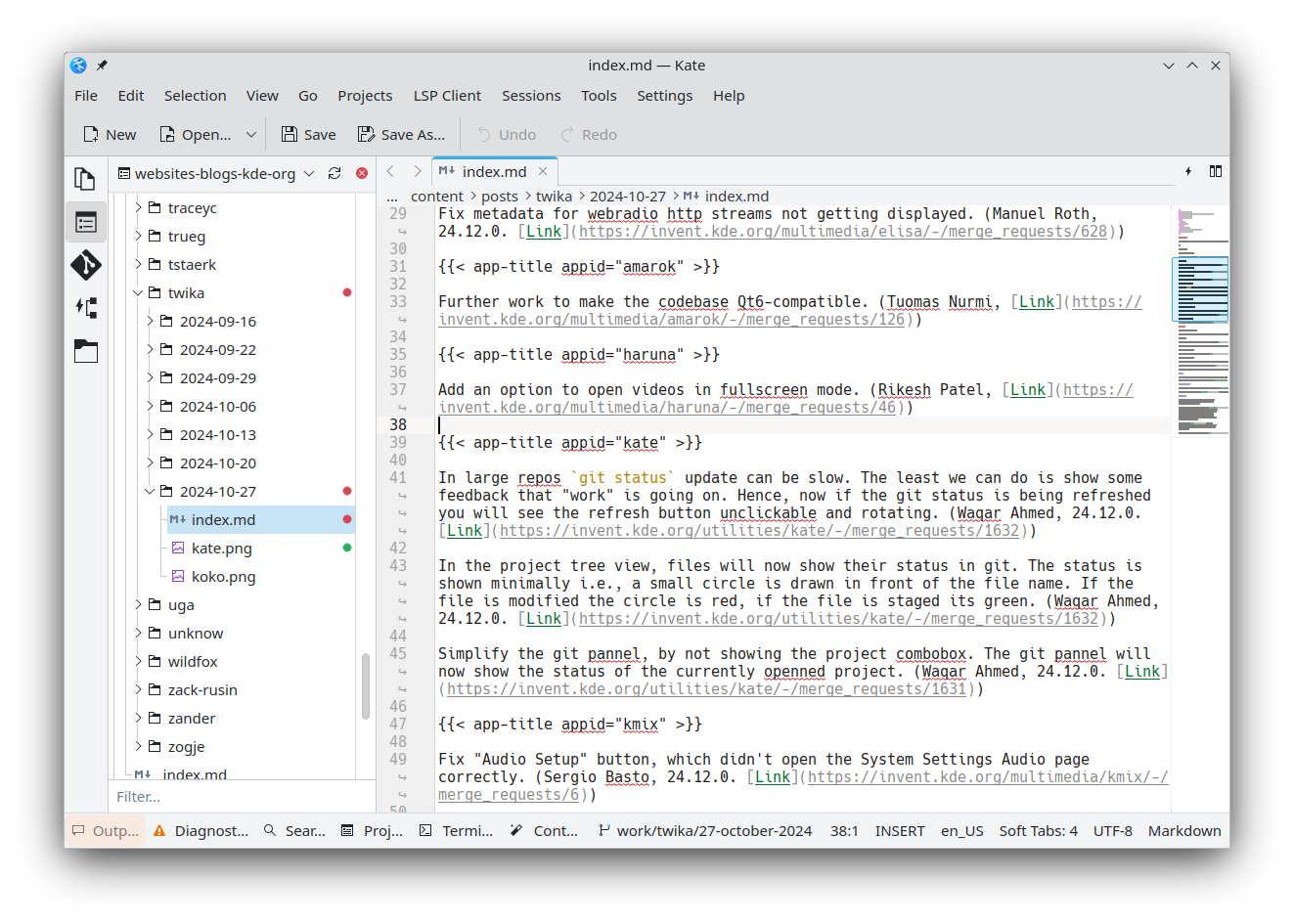
We simplified the git panel by hiding the project combobox. The git panel will now show the status of the currently opened project. (Waqar Ahmed, 24.12.0. Link)
We fixed the SQL plugin's SQL export being randomly ordered. (Waqar Ahmed, 24.08.3. Link)
Clock Keep time and set alarmsKClock's timer now shows the remaining time instead of the elapsed time. (Zhangzhi Hu, 24.12.0. Link)
KMix Sound MixerWe fixed the Audio Setup button, which didn't open the System Settings Audio page correctly. (Sergio Basto, 24.12.0. Link)
KMyMoney Personal finance manager based on double-entry bookkeepingIt's once again possible to download stock quotes from yahoo.com after they changed their output format. (Ralf Habacker, Link)
Reports can now be exported as PDF and XML. (Ralf Habacker, KMyMoney 5.2.0. Link 1, link 2)
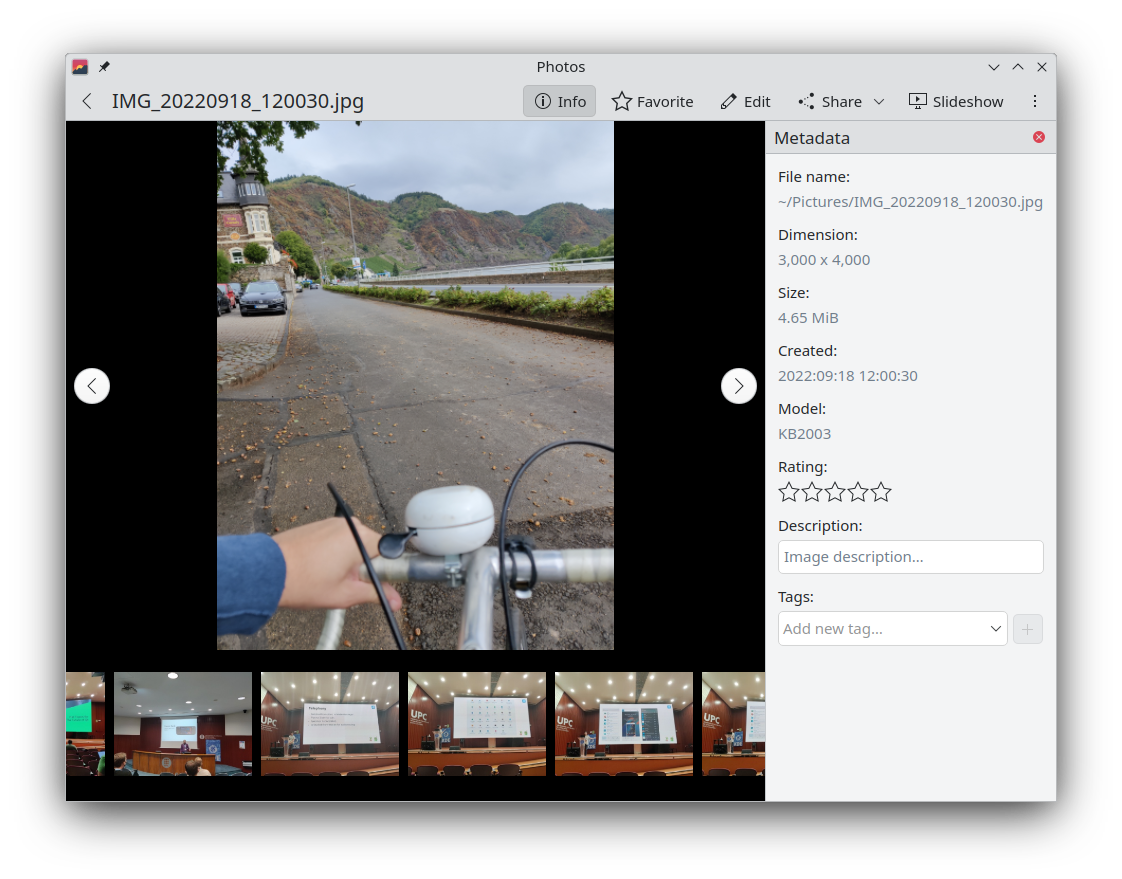
Photos Image GalleryWe improved the design of the properties panel. (Carl Schwan, 24.12.0. Link)
 Kleopatra Certificate manager and cryptography app
Kleopatra Certificate manager and cryptography app
The name of the "KWatchGnuPG" utility provided by Kleopatra has been updated to "GnuPG Log Viewer" (Carl Schwan, 24.12.0. Link) and we gave it a new logo.
 KleverNotes Take and manage your notes
KleverNotes Take and manage your notes
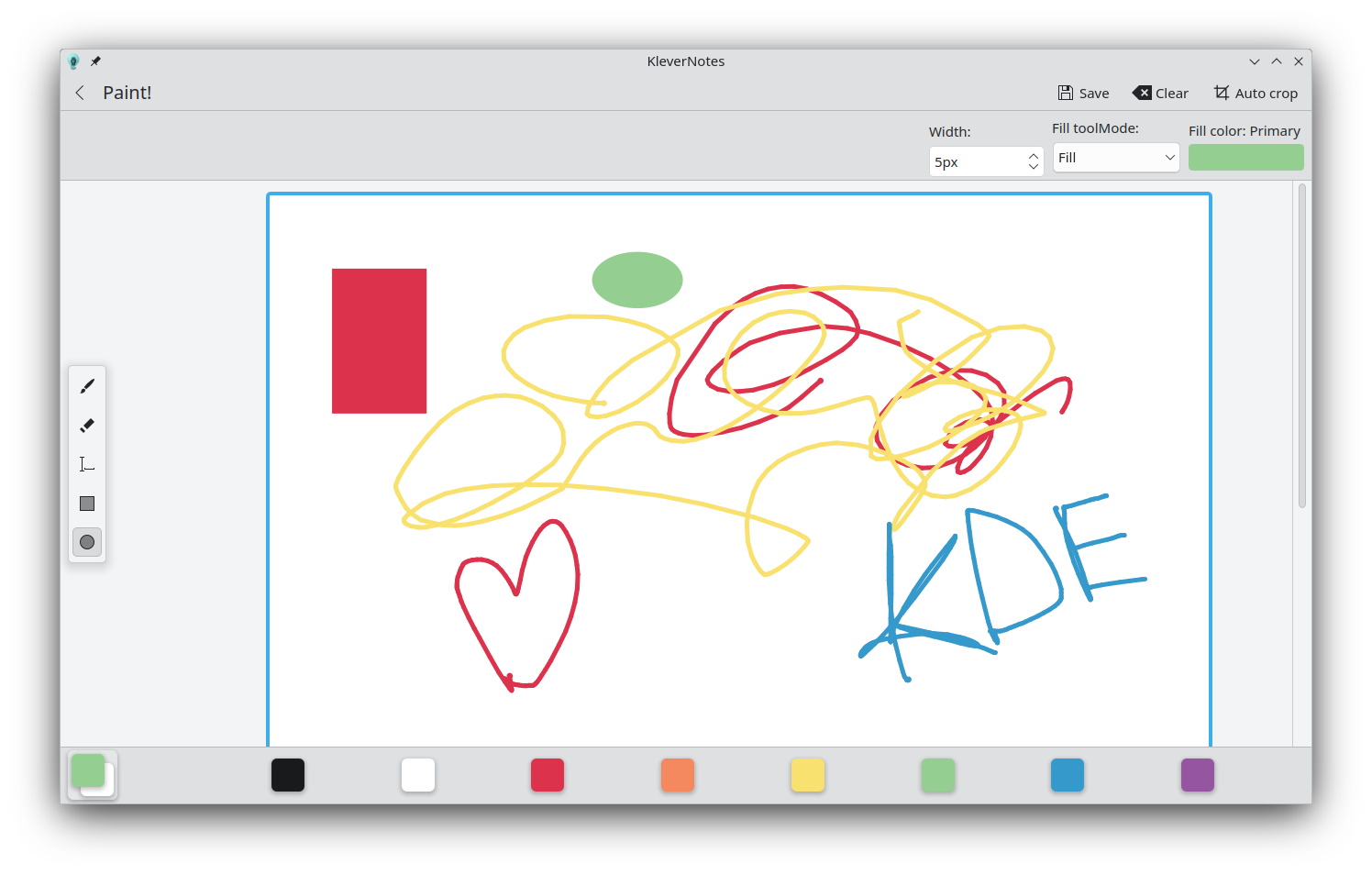
KleverNotes' painting mode has been completely rewritten. It is now possible to add circles, rectangles, labels, and to choose the stroke size. The UI also uses a new floating toolbar. (Louis Schul, 1.2.0. Link)
We improved the animation when switching pages. (Luis Schul, 1.2.0. Link)
The note preview in the appearance settings was simplified to only show the important parts. (Luis Schul, 1.2.0. Link)
KMail A feature-rich email applicationFix a crash in the Exchange Web Services (EWS) backend. (Louis Moureaux, 24.08.3. Link)
KRDC Connect with RDP or VNC to another computerWe fixed sharing folders. (Fabio Bas, 24.08.3. Link)
Merkuro Calendar Manage your tasks and events with speed and easeClaudio Cambra fixed adding and creating sub-todos (Claudio Cambra, 24.08.3. Link and Link)) and a bug that made clicking on the month view unreliable. (Claudio Cambra, 24.08.3, Link).
We also added back the maps showing the location of individual events. This was disabled during the Qt6 migration and never enabled back afterwards. (Claudio Cambra, 24.08.3, Link)
NeoChat Chat on MatrixSupport for libQuotient 0.9 has been backported to NeoChat 24.08. This brings, among other things, cross-signing support and support for the Matrix 1.12 API, including most importantly content repo functionality switching to authenticated media. (James Graham, 24.08.0, Link)
Okular View and annotate documentsAlbert Astals fixed switching between pages in the single-page mode when using a mouse with a "high resolution" scroll wheel. (Albert Astals Cid, 24.12.0. Link)
You can now use any image type as a signature background. (Sune Vuorela, 24.12.0. Link)
We removed the last CHM support mention in Okular and on the website. CHM support was dropped when transitioning to the Qt6 version. (Albert Astals Cid, 24.12.0. Link 1, link 2)
Zanshin To Do Management ApplicationFixed an issue where projects would be displayed twice when toggling on and off their data source. (David Faure, 24.08.3. Link)
And all this too...Justin Zobel fixed various appstream files to use the new way of declaring the developer's name. (Justin Zobel, KRuler, Gwenview, KEuroCalc, ...)
We ported various projects to use declarative QML declaration for better maintainance and performance (Carl Schwan, Koko, Francis, Kalk).
... And Everything ElseThis blog only covers the tip of the iceberg! If you’re hungry for more, check out Nate's blog about Plasma and be sure not to miss his This Week in Plasma series, where every Saturday he covers all the work being put into KDE's Plasma desktop environment.
For a complete overview of what's going on, visit KDE's Planet, where you can find all KDE news unfiltered directly from our contributors.
Get InvolvedThe KDE organization has become important in the world, and your time and contributions have helped us get there. As we grow, we're going to need your support for KDE to become sustainable.
You can help KDE by becoming an active community member and getting involved. Each contributor makes a huge difference in KDE — you are not a number or a cog in a machine! You don’t have to be a programmer either. There are many things you can do: you can help hunt and confirm bugs, even maybe solve them; contribute designs for wallpapers, web pages, icons and app interfaces; translate messages and menu items into your own language; promote KDE in your local community; and a ton more things.
You can also help us by donating. Any monetary contribution, however small, will help us cover operational costs, salaries, travel expenses for contributors and in general just keep KDE bringing Free Software to the world.
To get your application mentioned here, please ping us in invent or in Matrix.
OSM Hack Weekend October 2024
Last weekend I attended the bi-annual OSM Hack Weekend in Karlsruhe again, organized by Geofabrik and this time hosted at a nearby university building due to the large number of participants.
TransitousMy main focus has been getting the public transport client library used by KDE Itinerary ready for MOTIS v2, as Transitous, our community-run public transport routing service, will switch to that in the not too distant future.
One big new feature in MOTIS v2 is support for GTFS shapes. That is, getting detailed paths for public transport sections, beyond just positions of intermediate stops, which allows for a much more useful map display for example.
Even more importantly, MOTIS now also provides detailed multi-floor paths for transfers or other parts of a trip where you have to move yourself (walking, biking, etc). This is all based on OSM data and thus matches perfectly to the map data, but since practically no other backend provides this level of detail it also required a few changes in our data model and API.
Besides the new MOTIS API being much more intuitive than the previous one having had Felix from the MOTIS team around (even if just online) who instantly implemented all suggested improvements in the server made this super productive.
If your region isn’t covered by Transitous yet, check out the contributor documentation on how to change that.
ItineraryFor debugging parsing of paths provided by MOTIS I added a map view to the KPublicTransport demo app. That ended up getting close to what we’d need for a map view of an entire trip in Itinerary, so we also have that now. It’s not where I’d like it yet e.g. regarding interactivity and the look of bi-directional paths it’s a good start.
 Trip map view prototype in Itinerary.
Trip map view prototype in Itinerary.
A full trip map view was also one of the feature requests I got from other participants. Another suggestions that came up and that meanwhile has been implemented is pre-filling the stop location history with all locations involved in the current trip, which is quite helpful during trip planning.
Indoor RoutingFollowing a discussion on detailed mapping of hedges in outdoor mazes I learned there’s an OSM wiki page on that subject, which also lists a bunch of examples.
While I don’t really have any particular interest in outdoor mazes and/or fancy hedge art, these things just ask for being used as a test case for our indoor router.
 Indoor router finding a way through a maze made out of hedges.
You can help!
Indoor router finding a way through a maze made out of hedges.
You can help!
Hack weekends how this is called in the OSM community or sprints as this is known in the KDE community are immensely valuable and productive. There’s a great deal of knowledge transfer happening, and they are a big motivational boost.
However, physical meetings incur costs, and that’s where your donations help! KDE e.V. and local OSM chapters like the FOSSGIS e.V. support these activities.
This week in Plasma: all screens, all the time
We continued fixing bugs and making UI improvements this week. You’ll notice a good many of them are about screens somehow! Ah, screens, the magical windows to our computers. They are amazing… and they suck. So many graphics driver bugs and hardware quirks to work around, so many edge cases to handle… and so that was a large part of what we spent doing for you, dear reader! Because getting all this screen stuff right has a massive impact on quality.
And of course there was a lot of other work too!
Notable UI ImprovementsThere’s a new behavior when dragging things out of a window that’s not the top one in the stacking order: the window with the dragged content remains where it is during the drag, instead of immediately jumping to the front (Xaver Hugl, Plasma 6.3.0. Link)
Kickoff, Kicker, and other launcher menus now have a “Help” category, and the Help Center app appears there instead of among other top-level categories (me: Nate Graham, Plasma 6.3 and KHelpCenter 24.12. Link 1, link 2, and link 3):

Added a touch-friendly UI for the clipboard widget that appears only when in touch mode (Fushan Wen, Plasma 6.3.0. Link)
Fixed a case where some system components’ default shortcuts all wanted to use Meta+0 and interfered with one another. Now they all use different shortcuts:
- “Zoom to Actual Size” remains Meta+0
- “Manually Invoke Action on Current Clipboard” and “Activate Task Manager Entry 10” no longer have a default shortcut set
(Zhangzhi Hu, Plasma 6.3.0. Link)
WireGuard VPNs are now considered VPNs by the Networks widget, and labeled and grouped accordingly (Ivan Tkachenko, Plasma 6.3.0. Link)
Multi-instance or multi-process Flatpak apps are now grouped together and shown as only one app on System Monitor’s Applications page (Arjen Hiemstra, Plasma 6.3.0. Link):

SDDM themes that are actually just symlinks to other themes are now filtered out of the relevant page in System Settings (Bruno Ivan, Plasma 6.3.0. Link)
Capped the maximum width of the Bluetooth file transfer error dialog so it can’t be ridiculously wide (Zhangzhi Hu, Plasma 6.3.0. Link)
Added Breeze icons for Typst files (MV Puccino, Frameworks 6.8. Link)
A bunch of symbolic Breeze icons that were inappropriately symbolic-but-colorful are now monochrome to better match all the other monochrome symbolic icons (me: Nate Graham, Frameworks 6.8. Link)
Notable Bug FixesFixed a bug that could cause KWin to freeze when plugging in a Valve Index VR headset when there are no other screens enabled (Xaver Hugl, Plasma 6.2.2. Link)
Fixed a case where Plasma could crash when interacting with connected storage devices in certain ways (Fushan Wen, Plasma 6.2.2. Link)
Fixed a bug that would cause the positions of recently-renamed desktop files to not be saved to the config file correctly (Akseli Lahtinen, Plasma 6.2.2. Link). And on this subject, we’re currently deep into the process of fixing a related bug that causes icons to get scrambled when some (but not all) screens are turned off. Not for this week, but maybe next week!
Fixed a set of regressions that caused System Settings’ main window to not remember its size correctly (Akseli Lahtinen, Plasma 6.2.2 with Frameworks 6.8. Link)
Fixed a recent regression that made certain styles of user avatar image not get applied properly on System Settings’ Users page (Harald Sitter, Plasma 6.2.3. Link)
Spectacle no longer fails to save MP4-formatted screen recordings some of the time (Arjen Hiemstra, Plasma 6.2.3. Link)
You can now do a rectangular region screencast on any screen in a multi-screen setup, not just the left-most one (David Redondo, Plasma 6.2.3. Link)
The “Maximum time before updates” setting for grid-style System Monitor widgets now works (Arjen Hiemstra, Plasma 6.2.3. Link)
Worked around a quirk of certain HDR-capable screens screens that caused them to leave HDR move whenever any other display settings were changes (Xaver Hugl, Plasma 6.2.3. Link)
The “Forget all” menu item of Task Manager Task context menus now succeeds at forgetting abstract resources like URLs (Jin Liu, Plasma 6.2.3. Link)
Made it more reliable to save custom names given to audio devices (Harald Sitter, Plasma 6.2.3. Link)
Fixed a case where the ksystemstats background service that provides information to System Monitor and its widgets’ could crash due to a recent change in Qt (Arjen Hiemstra, Plasma 6.3.0. Link)
Fixed a case where Plasma and other KDE apps could crash when ejecting a CD (Nicolas Fella, Frameworks 6.8. Link)
When your user account is slightly misconfigured and does not define a templates directory, the “Create New” menu does no longer weirdly populates itself with the entire contents of your home folder (Benjamin Gonzalez, Frameworks 6.8. Link)
Fixed an issue that could cause the setting to govern notification sound level to not appear as expected (Harald Sitter, Pulseaudio-Qt 1.6.1. Link)
Fixed a bug that could cause the pointer’s target to get sort of stuck after dragging things until after the first click following the completion of the drag. This was commonly seen when re-arranging Task Manager entries: if you failed to click once after dragging an app, the next drag would target the preciously-dragged app instead of the one you wanted (David Edmundson, Qt 6.8.1. Link)
Other bug information of note:
- 5 Very high priority Plasma bug (up from 4 last week). Current list of bugs
- 35 15-minute Plasma bugs (up from 33 last week). Current list of bugs
- 129 KDE bugs of all kinds fixed over the last week. Full list of bugs
Improved the reliability of the “remember for next time” feature in the screen recording source chooser window (David Redondo, Plasma 6.3. Link)
Reduces a source of slowness in the Task Manager widget when faced with windows that have hundreds or thousands of characters in their titles (Jin Liu, Plasma 6.2.3. Link)
The Night Light feature now tints the screen in a colorimetrically correct way when not using ICC profiles (Xaver Hugl, Plasma 6.3.0. Link)
It’s now possible to use Plasma scripting to change panels’ opacity levels or what screen they appear on (Heitor Augusto Lopes Nunes and Devin Lin, Plasma 6.3.0. Link 1 and link 2)
How You Can HelpIf you’re a developer, keep on working to fix Plasma 6.2 regressions! We’ve got ’em on the run, and this is our chance to finish them off!
Otherwise, visit https://community.kde.org/Get_Involved to discover additional ways to be part of a project that really matters. Each contributor makes a huge difference in KDE; you are not a number or a cog in a machine! You don’t have to already be a programmer, either. I wasn’t when I got started. Try it, you’ll like it! We don’t bite! Or consider donating instead! That helps too.
Web Review, Week 2024-43
Let’s go for my web review for the week 2024-43. It’s published later than usual since I’m attending the Ubuntu Summit 2024 and had to travel because of it.
Microsoft maintains its own Windows debloat scripts on GitHubTags: tech, microsoft, criticism, funny
This is indeed telling unfortunately. It’s kind of ironic that they felt the need of having their own debloat scripts.
https://www.osnews.com/story/140955/microsoft-maintains-its-own-windows-debloat-scripts-on-github/
Tags: tech, democracy, politics
This is just insane, claiming two opposite things to different demographic groups for political gains. And if you try to stop this kind of manipulative stunts they’d probably cry wolf about free speech…
Tags: tech, ai, machine-learning, gpt, economics, energy, criticism
More signs of the current bubble being about to burst?
Tags: tech, ai, machine-learning, gpt, criticism
This is what you get by making bots spewing text based on statistics without a proper knowledge base behind it.
Tags: tech, ai, gpt, copilot, language
Using the right metaphors will definitely help with the conversation in our industry around AI. This proposal is an interesting one.
https://www.dbreunig.com/2024/10/18/the-3-ai-use-cases-gods-interns-and-cogs.html
Tags: cognition, neuroscience, language, logic, knowledge, research
Very interesting research. Looks like we’re slowly moving away from the “language and thinking are intertwined” hypothesis. This is probably the last straw for Chomsky’s theory of language. It served us well but neuroscience points that it’s time to leave it behind.
https://www.scientificamerican.com/article/you-dont-need-words-to-think/
Tags: tech, ai, machine-learning, gpt, logic, research
Now this is an interesting paper. Neurosymbolic approaches are starting to go somewhere now. This is definitely helped by the NLP abilities of LLMs (which should be used only for that). The natural language to Prolog idea makes sense, now it needs to be more reliable. I’d be curious to know how many times the multiple-try path is exercised (the paper doesn’t quite focus on that). More research is required obviously.
https://arxiv.org/abs/2407.11373
Tags: tech, ai, machine-learning, gpt, optimization
More marketing announcement than real research paper. Still it’s nice to see smaller models being optimized to run on mobile devices. This will get interesting when it’s all local first and coupled to symbolic approaches.
https://ai.meta.com/blog/meta-llama-quantized-lightweight-models/
Tags: tech, statistics, ai, machine-learning, gpt, language
This is still an important step with LLM. It’s not because the models are huge that tokenizers disappeared or that you don’t need to clean up your data.
https://cybernetist.com/2024/10/21/you-should-probably-pay-attention-to-tokenizers/
Tags: tech, markdown, qt, note-taking, tools
Ah! I wish MarkNotes or KleverNotes would work like this. I wish we’d have a reusable component in KDE Frameworks too. This is quite some work of course, too bad this isn’t FOSS.
https://rubymamistvalove.com/block-editor
Tags: tech, browser, firefox, bookmarks
A very useful but indeed little known feature of Firefox bookmarks.
https://paper.wf/binarycat/bookmark-keywords
Tags: tech, internet, protocols, ip
Looks like we’re stuck in the middle of the bridge. Also looks like the motivation to finish the transition isn’t high.
https://www.potaroo.net/ispcol/2024-10/ipv6-transition.html
Tags: tech, programming, unix, security
Good reminder that /tmp has many security flaws built in.
https://dotat.at/@/2024-10-22-tmp.html
Tags: tech, databases, postgresql, design
Since everything has design choices which imply trade offs. Here is the main issue with PostgreSQL right now. Hopefully it’ll get modernized at some point.
https://www.cs.cmu.edu/~pavlo/blog/2023/04/the-part-of-postgresql-we-hate-the-most.html
Tags: tech, backend, databases, sqlite
Another nice list of defaults for SQLite. Some of them I didn’t have on my radar.
https://briandouglas.ie/sqlite-defaults/
Tags: tech, python, developer-experience
uv keeps showing promise to make development easier. It makes everything very much self contained.
https://til.simonwillison.net/python/uv-cli-apps
Tags: tech, programming, debugging
Definitely a sound advice. You don’t want to be confused when debugging something because it looks too much like a variable or a property name.
https://registerspill.thorstenball.com/p/use-data-that-looks-like-data
Tags: tech, tests, python
Another example of why pytest is really a nice test runner. I really miss it on projects which don’t have it.
https://mathspp.com/blog/til/pytest-selection-arguments-for-failing-tests
Tags: tech, tests
Indeed a good way to reason about tests and the value they bring.
https://testing.googleblog.com/2024/10/smurf-beyond-test-pyramid.html?m=1
Tags: tech, career, engineering, craftsmanship, complexity
Another good set of advices. They’re not all technical which is to be expected.
https://blog.rpanachi.com/after-25-years-writing-software-here-some-things-learned-so-far
Tags: tech, framework, complexity, knowledge, learning, debugging, craftsmanship
I very much agree with this. The relationship between developers and their frameworks is rarely healthy. I think the author misses an important advice though: read the code of your frameworks. When stuck invest sometime stepping into the frameworks with the debugger. Developers too often treat those as a black box.
https://prahladyeri.github.io/blog/2024/10/framework-overload.html
Tags: tech, learning, career
Definitely the most important skill to develop. Especially in our profession.
https://kevin.the.li/posts/learning-to-learn/
Tags: tech, management, career, hr
Lots of open questions which are left unanswered. That said it shows how difficult it is to evaluate knowledge workers in general and that we’re often grasping to the wrong metrics.
https://chelseatroy.com/2024/03/29/how-do-we-evaluate-people-for-their-technical-leadership/
Tags: management, transparency, fair
Transparency and fairness are definitely important to keep people motivated across an organization. That doesn’t make it easy to deal with of course, but that’s where managers should focus.
https://read.perspectiveship.com/p/fairness-at-work
Bye for now!
Design System – Colors, Variables and Tokens!
This week, we realized that there are a few things we need to do to button-down our use of colors in a way that makes sense, not just for designers but also for developers.
As we find inspiration on what others are doing, we will make a couple of changes in the design system when it comes to colors.
- Select UI colors using HCT color methodology.
- Adopt a similar variable/token naming strategy as Material Design
As suggested by team members, the HCT color selection methodology has a few advantages:
- Accessibility
- Standard calculation method for color selection rather than by doing manual contrast calculations. This allows for all selected colors to be separated and distinct-enough from each other that users can see color differences in their applications.
- Perceptual accuracy
- HCT allows for seeing colors more accurately at a perceptual level.
- Consistent lightness and colorfulness
- Consistent lightness and colorfulness across hues.
- Precise color and tonal accuracy
- More precise color and tonal accuracy, especially in dark shadows and richly-saturated colors.
- Higher dynamic range and wider color gamut
- Provides a wider color gamut and higher dynamic range than typical camera targets.
In our team, we have 3 people currently working on this. Not only are we selecting colors, but also creating a color-use system that all users can understand.
Building logic use into the colors allows for less dependence on people but something we can document and anyone looking at it would be able to understand regardless of their specialty.
TokensA few of the questions we had as a team while producing the design system were, how can we make it so that developers and designers understand all the pieces used in the design system, but at a development level?
One of the things that applications such as Figma and PenPot allow is for designers to define the names of each of the elements used in a design. We create variables names for stuff like fonts and colors. However, while that’s helpful, we also have to have logic behind the naming so that our developer friends are not confused by the use of variable names in the design system.
For this purpose, design system creators often use a token system that ensures naming between the design system and development is consistent, predictable, and useful.
Material design has a robust naming idea around tokens. It works a little like this:
The types of tokens are:
- Reference tokens
All available tokens with associated values - System tokens
Decisions and roles that give the design system its character, from color and typography, to elevation and shape - Component tokens
The design attributes assigned to elements in a component, such as the color of a button icon
 https://m3.material.io/foundations/design-tokens/how-to-read-tokens: Design System – Colors, Variables and Tokens!
https://m3.material.io/foundations/design-tokens/how-to-read-tokens: Design System – Colors, Variables and Tokens!
We consulted with the team members and it seems like a good strategy. Right now, we don’t have any of the reference or system tokens but we use component tokens in some capacities. The idea is to create and organize the naming conventions around the token ideas from Material. We may still decide to change some of the naming conventions but keep the general idea.
Note that we don’t have the intention of replacing current tokens. The process would be to add new ones that developers would begin using over time while keeping the ones we already have.
What this means for us in the design system, is that we will change our design variables to reflect this organization and when communicating the changes to the dev team, we will provide tables showing all the variables/tokens used. It will also contain which elements of the design system are included in a reference, system, or component token.
If you would like to participate of this effort, you’re welcome to join us here:
Our channel is dedicated to working on the design system. For general Visual Design questions, you can access our team here:
https://matrix.to/#/#visualdesigngroup:kde.org
Calamares towards 3.3.11
I’m going to change up the Calamares release process a little. It’s been slow going as a community-maintained project – which isn’t to say that that is a bad thing. Just slow. I’ve decided to make releases marginally more predictable than “when [ade] has a relaxed kind of Tuesday” and have marked a couple of issues with the Calamares 3.3 milestone. When the milestone is empty again, then there will be a release. After the next release, I’ll put a couple more issues on the milestone, and the recipe can be repeated.
EBN lives?
Many years ago I was involved in software-quality research – the SQO-OSS project and things like that. That work begat the code-quality checking scripts that we in the KDE community called “the EBN”, or EnglishBreakfastNetwork. I was a tea-drinker then. The EBN stuff has been surpassed by Klazy and many other software-quality-checking tools. But the EBN domain carries on. Although I haven’t got anything to put on it I just renewed the domain again for two years – just in case.
10 Tips to Make Your QML Code Faster and More Maintainable
In recent years, a lot has been happening to improve performance, maintainability and tooling of QML. Some of those improvements can only take full effect when your code follows modern best practices. Here are 10 things you can do in order to modernize your QML code and take full advantage of QML’s capabilities.
1. Use qt_add_qml_module CMake APIQt6 introduced a new CMake API to create QML modules. Not only is this more convenient than what previously had to be done manually, but it is also a prerequisite for being able to exploit most of the following tips.
By using the qt_add_qml_module, your QML code is automatically processed by qmlcachegen, which not only creates QML byte code ahead of time, but also converts parts of your QML code to C++ code, improving performance. How much of your code can be compiled to C++ depends on the quality of the input code. The following tips are all about improving your code in that regard.
add_executable(myapp main.cpp) qt_add_qml_module(myapp URI "org.kde.myapp" QML_FILES Main.qml ) 2. Use declarative type registrationWhen creating custom types in C++ and registering them with qmlRegisterType and friends, they are not visible to the tooling at the compile time. qmlcachegen doesn’t know which types exist and which properties they have. Hence, it cannot translate to C++ the code that’s using them. Your experience with the QML Language Server will also suffer since it cannot autocomplete types and property names.
To fix this, your types should be registered declaratively using the QML_ELEMENT (and its friends, QML_NAMED_ELEMENT, QML_SINGLETON, etc) macros.
qmlRegisterType("org.kde.myapp", 1, 0, "MyThing");becomes
class MyThing : public QObject { Q_OBJECT QML_ELEMENT };The URL and version information are inferred from the qt_add_qml_module call.
3. Declare module dependenciesSometimes your QML module depends on other modules. This can be due to importing it in the QML code, or more subtly by using types from another module in your QML-exposed C++ code. In the latter case, the dependency needs to be declared in the qt_add_qml_module call.
For example, exposing a QAbstractItemModel subclass to QML adds a dependency to the QtCore (that’s where QAbstractItemModel is registered) to your module. This does not only happen when subclassing a type but also when using it as a parameter type in properties or invokables.
Another example is creating a custom QQuickItem-derived type in C++, which adds a dependency on the Qt Quick module.
To fix this, add the DEPENDENCIES declaration to qt_add_qml_module:
qt_add_qml_module(myapp URI "org.kde.myapp" QML_FILES Main.qml DEPENDENCIES QtCore ) 4. Qualify property types fullyMOC needs types in C++ property definitions to be fully qualified, i.e. include the full namespace, even when inside that namespace. Not doing this will cause issues for the QML tooling.
namespace MyApp { class MyHelper : public QObject { Q_OBJECT }; class MyThing : public QObject { Q_OBJECT QML_ELEMENT Q_PROPERTY(MyHelper *helper READ helper CONSTANT) // bad Q_PROPERTY(MyApp::MyHelper *helper READ helper CONSTANT) // good ... }; } 5. Use typesIn order for qmlcachegen to generate efficient code for your bindings, it needs to know the type for properties. Avoid using ‘property var’ wherever possible and use concrete types. This may be built-in types like int, double, or string, or any declaratively-defined custom type. Sometimes you want to be able to use a type as a property type in QML but don’t want the type to be creatable from QML directly. For this, you can register them using the QML_UNCREATABLE macro.
property var size: 10 // bad property int size: 10 // good property var thing // bad property MyThing thing // good 6. Avoid parent and other generic propertiesqmlcachegen can only work with the property types it knows at compile time. It cannot make any assumptions about which concrete subtype a property will hold at runtime. This means that, if a property is defined with type Item, it can only compile bindings using properties defined on Item, not any of its subtypes. This is particularly relevant for properties like ‘parent’ or ‘contentItem’. For this reason, avoid using properties like these to look up items when not using properties defined on Item (properties like width, height, or visible are okay) and use look-ups via IDs instead.
Item { id: thing property int size: 10 Rectangle { width: parent.size // bad, Item has no 'size' property height: thing.height // good, lookup via id color: parent.enabled ? "red" : "black" // good, Item has 'enabled' property } } 7. Annotate function parameters with typesIn order for qmlcachegen to compile JavaScript functions, it needs to know the function’s parameter and return type. For that, you need to add type annotations to the function:
function calculateArea(width: double, height: double) : double { return width * height }When using signal handlers with parameters, you should explicitly specify the signal parameters by supplying a JS function or an arrow expression:
MouseArea { onClicked: event => console.log("clicked at", event.x, event.y) }Not only does this make qmlcachegen happy, it also makes your code far more readable.
8. Use qualified property lookupQML allows you to access properties from objects several times up in the parent hierarchy without explicitly specifying which object is being referenced. This is called an unqualified property look-up and generally considered bad practice since it leads to brittle and hard to reason about code. qmlcachegen also cannot properly reason about such code. So, it cannot properly compile it. You should only use qualified property lookups
Item { id: root property int size: 10 Rectangle { width: size // bad, unqualified lookup height: root.size // good, qualified lookup } }Another area that needs attention is accessing model roles in a delegate. Views like ListView inject their model data as properties into the context of the delegate where they can be accessed with expressions like ‘foo’, ‘model.foo’, or ‘modelData.foo’. This way, qmlcachegen has no information about the types of the roles and cannot do its job properly. To fix this, you should use required properties to fetch the model data:
ListView { model: MyModel delegate: ItemDelegate { text: name // bad, lookup from context icon.name: model.iconName // more readable, but still bad required property bool active // good, using required property checked: active } } 9. Use pragma ComponentBehavior: BoundWhen defining components, either explicitly via Component {} or implicitly when using delegates, it is common to want to refer to IDs outside of that component, and this generally works. However, theoretically any component can be used outside of the context it is defined in and, when doing that, IDs might refer to another object entirely. For this reason, qmlcachegen cannot properly compile such code.
To address this, we need to learn about pragma ComponentBehavior. Pragmas are file-wide switches that influence the behavior of QML. By specifying pragma ComponentBehavior: Bound at the top of the QML file, we can bind any components defined in this file to their surroundings. As a result, we cannot use the component in another place anymore but can now safely access IDs outside of it.
pragma ComponentBehavior: Bound import QtQuick Item { id: root property int delegateHeight: 10 ListView { model: MyModel delegate: Rectangle { height: root.delegateHeight // good with ComponentBehavior: Bound, bad otherwise } } }A side effect of this is that accessing model data now must happen using required properties, as described in the previous point. Learn more about ComponentBehavior here.
10. Know your toolsA lot of these pitfalls are not obvious, even to seasoned QML programmers, especially when working with existing codebases. Fortunately, qmllint helps you find most of these issues and avoids introducing them. By using the QML Language Server, you can incorporate qmllint directly into your preferred IDE/editor such as Kate or Visual Studio Code.
While qmlcachegen can help boost your QML application’s performance, there are performance problems it cannot help with, such as scenes that are too complex, slow C++ code, or inefficient rendering. To investigate such problems, tools like the QML profiler, Hotspot for CPU profiling, Heaptrack for memory profiling, and GammaRay for analyzing QML scenes are very helpful.
If you like this article and want to read similar material, consider subscribing via our RSS feed.
Subscribe to KDAB TV for similar informative short video content.
KDAB provides market leading software consulting and development services and training in Qt, C++ and 3D/OpenGL. Contact us.
The post 10 Tips to Make Your QML Code Faster and More Maintainable appeared first on KDAB.
Ensuring Product Longevity With Qt Long-Term Support

As we continue to evolve and adapt the Qt Framework to the needs of our users and upcoming regulation changes, we are excited to announce some significant changes to our Long-Term Support (LTS) policy from Qt 6.8 onwards. The changes are designed to provide a more robust and predictable support strategy, ensuring your projects remain secure and stable over their entire lifecycle.
KDE and Google Summer of Code 2024

All but one of KDE's Google Summer of Code (GSoC) projects are complete. This post will summarize the completed project outcomes. GSoC is a program where people who are students or are new to Free and Open Source software make programming contributions to an open source project.
Projects Arianna- Port Arianna to Foliate-js: Ajay Chauhan worked on porting Arianna from epub.js to use Foliate-js. The work will hopefully be merged soon.
 A screenshot of Arianna using Foliate-js to render a table of contents
A screenshot of Arianna using Foliate-js to render a table of contents(Courtesy of Ajay Chauhan, all rights reserved) Frameworks
Python bindings for KDE Frameworks:
Manuel Alcaraz Zambrano, implemented Python bindings for KWidgetAddons, KUnitConversion, KCoreAddons, KGuiAddons, KI18n, KNotifications, and KXmlGUI. This was done using Shiboken. In addition, Manuel wrote a tutorial on how to generate Python bindings using Shiboken. The complicated set of merge requests are still being reviewed, and Manuel continues to interact with the KDE community.
 Unit conversion example created using Python and KUnitConversion
Unit conversion example created using Python and KUnitConversion(Courtesy of Manuel Alcaraz Zambrano, CC BY-NC-SA 4.0) KDE Connect
Update SSHD library in KDE Connect Android app
The main aim of ShellWen Chen's project was to update Apache Mina SSHD from 0.14.0 to 2.12.1. The older version has a few listed vulnerabilities. The newer library required additional code to enable it to work on older Android phones, upto Android API 21.
KDE GamesImplementing a computerized opponent for the Mancala variant Bohnenspiel:
João Gouveia created Mankala engine, a library to enable easy creation of Mancala games. The engine contains implementations for two Mancala games, Bohnenspiel and Oware. Both games contain computerized opponents, João also started on a QtQuick graphical user interface. The games are functional, but additional investigation on computerized opponents may help improve their effectiveness.
 Image of text user interface for Bohnenspiel
Image of text user interface for Bohnenspiel(Courtesy of João Gouveia, CC BY-SA 4.0) Kdenlive
Improved subtitling support for Kdenlive:
Kdenlive has gotten improved subtitling support. Chengkun Chen added support for using the Advanced SubStation (ASS) file format and for converting SubRip files to ASS files. To support this format, Chengkun Chen also made subtitling editor improvements. The work has been merged in the main repository. Documentation has been written, and will hopefully be merged soon.
 The new Style Editor Widget
The new Style Editor Widget(Courtesy of Chengkun Chen, CC BY-SA 4.0) Krita
Creating Pixel Perfect Tool for Krita:
Ken Lo worked on implementing Pixel Perfect lines in Krita. As explained by Ricky Han, such algorithms remove corner pixels from L shaped blocks and ensure the thinnest possible line is 1 pixel wide. Implementing such algorithms well is of use not only in Krita, but also in rendering web graphics where user screen resolutions can vary significantly. The algorithm was implemented to work in close to real time while lines are drawn, rather than as a post processing step. Ken Lo's work has been merged into Krita.
 An image showing that pixel perfect lines are obtained most of the time
An image showing that pixel perfect lines are obtained most of the time(Courtesy of Ken Lo, CC BY 4.0) Labplot
Improve Python Interoperability with LabPlot
Israel Galadima worked on improving Python support in LabPlot. Shiboken was used for this. It is now possible to call some of LabPlot functions from Python and integrate these into other applications.
 An image of a plot produced using Python bindings to Labplot
An image of a plot produced using Python bindings to Labplot(Courtesy of Israel Galadima, CC BY-SA 4.0)
Kuntal Bar added 3D graphing abilities to LabPlot. This was done using QtGraphs. The work has yet to be merged, but there are many nice examples of 3D plots, for bar charts, scatter and surface plots.
 A 3D bar chart
A 3D bar chart(Courtesy of Kuntal Bar, all rights reserved) Snaps
Improving Snap Ecosystem in KDE
Snaps are self contained linux application packging formats. Soumyadeep Ghosh worked on improving the tooling necessary to make KDE applications easily available in the Snap Store. In addition, Soumyadeep improved packaging of a number of KDE Snap packages, and packaged MarkNote. Finally, Soumyadeep created Snap KCM, a graphical user interface to manage permissions that Snaps have when running.
 Snap KCM
Snap KCM(Courtesy of Soumyadeep Ghosh, all rights reserved) Next Steps
The GSoC period is over, for all but one contributor, Pratham Gandhi. A follow up post will summarize contributions from the remaining project. Contributors have enjoyed participating in GSoC and we look forward to their continuing participation in free and open source software communities and in contributing to KDE.
KDE Plasma 6.2.2, Bugfix Release for October
Tuesday, 22 October 2024. Today KDE releases a bugfix update to KDE Plasma 6, versioned 6.2.2.
Plasma 6.2 was released in October 2024 with many feature refinements and new modules to complete the desktop experience.
This release adds a week's worth of new translations and fixes from KDE's contributors. The bugfixes are typically small but important and include:
- KWin Backends/drm: leave all outputs disabled by default, including VR headsets. Commit. Fixes bug #493148
- KWin Set WAYLAND_DISPLAY before starting wayland server. Commit.
- Plasma Audio Volume Control: Fix text display for auto_null device. Commit. Fixes bug #494324
Kdenlive 24.08.2 released
Kdenlive 24.08.2 is out with many fixes to a wide range of bugs and regressions.
- Fix title producer update on edit undo. Commit. Fixes bug #494142.
- Fix typo in dance.xml. Commit.
- Fix single item(s) move. Commit.
- Fix cycle effects playling timeline and sometimes broken after reopening project. Commit.
- Fix recent regression breaking all sort of things when opening projects. Commit.
- Fix crash when dragging clip and using mouse wheel. Commit.
- Don’t play when clicking monitor container if disabled in settings. Commit.
- Fix effect zones lost on project reopening. Commit.
- Various fixes for bin clip effects. Commit.
- Disable check for ghost effects that currently removes valid effects. Commit.
- Detect and fix track producers with incorrect effects. Commit.
- Fix bin effects sometimes not correctly removed from timeline instance. Commit.
- Don’t try to build clone effect it if does not apply to the target. Commit.
- Don’t unnecessarily check MLT tractors. Commit.
- Fix crash opening file with missing clips. Commit.
- Fix crash on project close. Commit.
- Fix compilation. Commit.
- Fix possible crash opening an interlaced project. Commit.
- Fix on monitor seek to next/previous keyframe buttons. Commit.
- Fix crash editing keyframes in a bin clip with grouped effects enabled. Commit.
- Don’t try to connect to dbus jobview on command line rendering. Commit.
- Fix Qt5 compilation. Commit.
- FIx looping through clips in project monitor effect scene. Commit.
- Fix loop selected clip. Commit.
The post Kdenlive 24.08.2 released appeared first on Kdenlive.
Akademy 2025 Call for Hosts
If you want to contribute to KDE in a significant way (beyond coding), here is your opportunity — help us organize Akademy 2025!
We are seeking hosts for Akademy 2025, which will occur in June, July, August, or September. This is your chance to bring KDE’s biggest event to your city! Download the Call for Hosts guide and submit your proposal to [email protected] by December 1, 2024.
Feel free to reach out with any questions or concerns! We are here to help you organise a successful event and are here to offer you any advice, guidance, or help you need. Let’s work together to make Akademy 2025 an event to remember.
Oxygen Icons 6.1.0
Oxygen Icons 6.1.0 is a feature release of the Oxygen Icon set.
It features new SVG symbolic icons for use in Plasma Applets.
It also features improved icon theme compliance, fixed visability and added mimetype links.
URL: https://download.kde.org/stable/oxygen-icons/
Source: oxygen-icons-6.1.0.tar.xz
SHA256: 16ca971079c5067c4507cabf1b619dc87dd6b326fd5c2dd9f5d43810f2174d68
Signed by: E0A3EB202F8E57528E13E72FD7574483BB57B18D Jonathan Riddell [email protected]
https://jriddell.org/jriddell.pgp