Planet KDE

More Icon Updates
I took some time last week to work on these icons some more. Here are the results:
KDiagram 3.0.1
KDiagram 3.0.1 is an update to our charting libraries which fixes a bug in the cmake path configuration. It also updates translations and removes some unused Qt 5 code.
URL: https://download.kde.org/stable/kdiagram/3.0.1/
sha256: 4659b0c2cd9db18143f5abd9c806091c3aab6abc1a956bbf82815ab3d3189c6d
Signed by E0A3EB202F8E57528E13E72FD7574483BB57B18D Jonathan Esk-Riddell [email protected]
https://jriddell.org/esk-riddell.gpg
Chingam: a new libre Malayalam traditional script font
‘Chingam’/ചിങ്ങം (named after the first month of Malayalam calendar) is the newest libre/open source font released by Rachana Institute of Typography in the year 2024.

It comes with a regular variant, embellished with stylistic alternates for a number of characters. The default shape of characters D, O, ഠ, ാ etc. are wider in stark contrast with the shape of other characters designed as narrow width. The font contains alternate shapes for these characters more in line with the general narrow width characteristic.
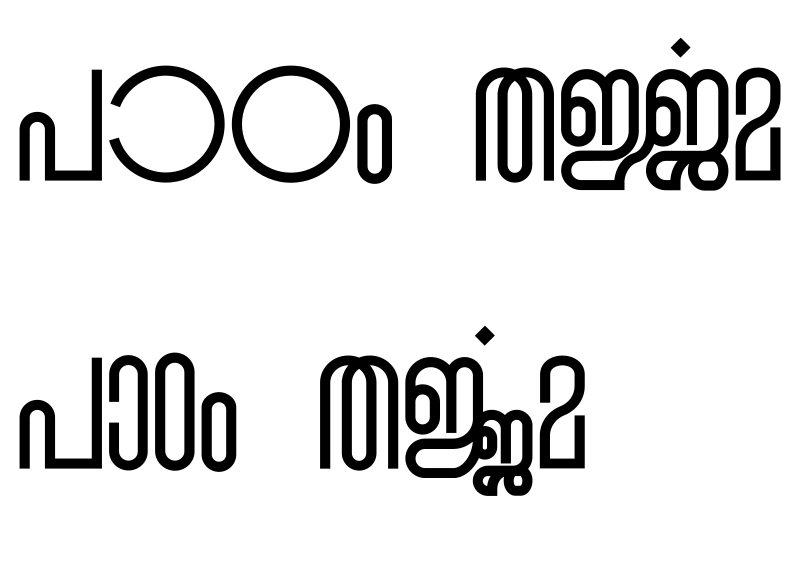
Users can enable the stylistic alternates in typesetting systems, should they wish.
- XeTeX: stylistic variant can be enabled with the StylisticSet={1} option when defining the font via fontspec package. For e.g.
\newfontfamily\chingam[Ligatures=TeX,Script=Malayalam,StylisticSet={1}]{Chingam}
…
\begin{document}
\chingam{മനുഷ്യരെല്ലാവരും തുല്യാവകാശങ്ങളോടും അന്തസ്സോടും സ്വാതന്ത്ര്യത്തോടുംകൂടി ജനിച്ചിട്ടുള്ളവരാണ്…}
\end{document}
- Scribus: extra font features are accessible since version 1.6
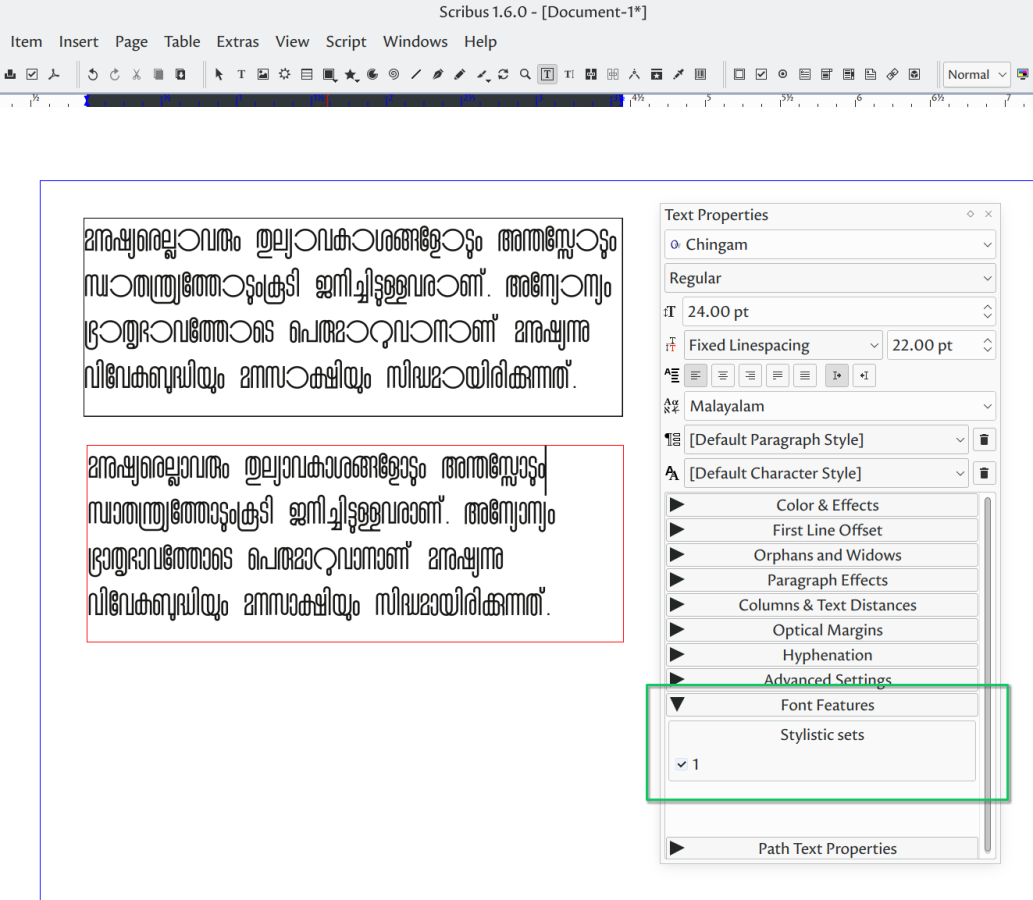
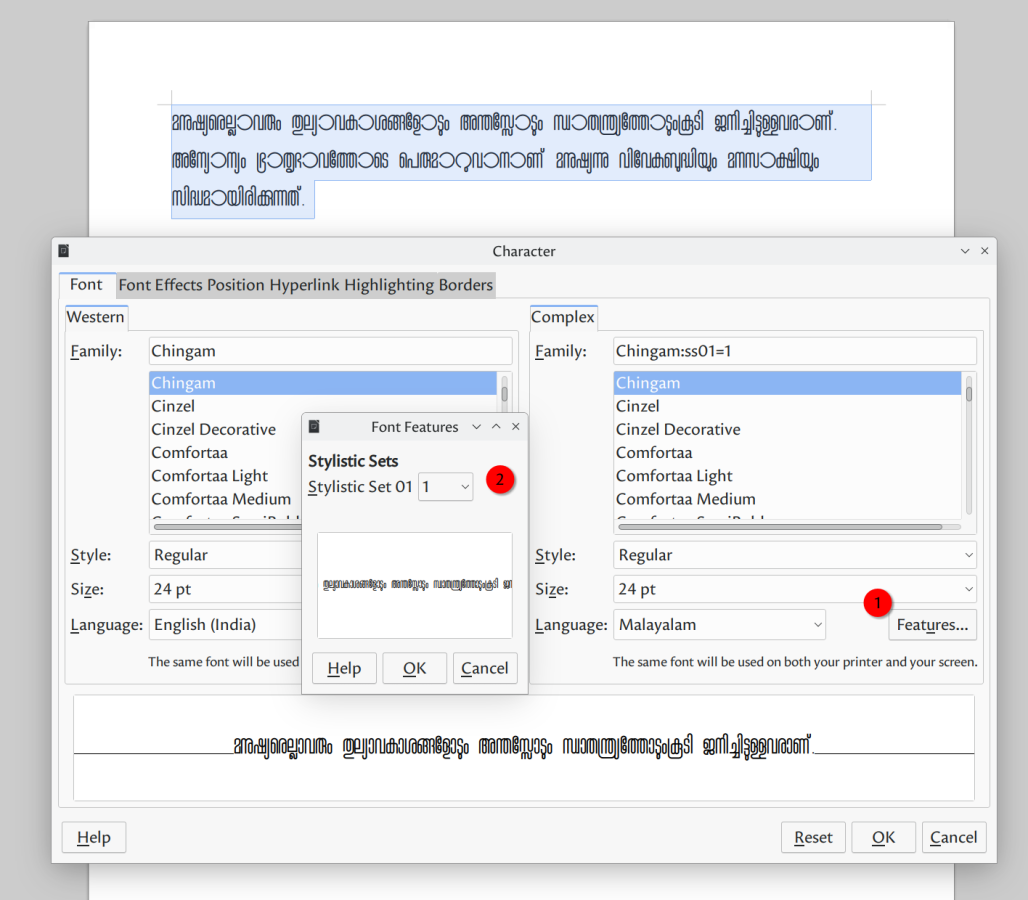
- LibreOffice: extra font features are accessible since version 7.4. Enable it using Format→Character→Language→Features.
- InDesign: very similar to Scribus; there should be an option in the text/font properties to choose the stylistic set.
Chingam is designed and drawn by Narayana Bhattathiri. Based on the initial drawings on paper, the glyph shapes are created in vector format (svg) following the glyph naming convention used in RIT projects. A new build script is developed by Rajeesh that makes it easier for designers to iterate & adjust the font metadata & metrics. Review & scrutiny done by CVR, Hussain KH and Ashok Kumar improved the font substantially.
DownloadChingam is licensed under Open Font License. The font can be downloaded from Rachana website, sources are available in GitLab page.
November and December in KDE PIM
Here's our bi-monthly update from KDE's personal information management applications team. This report covers progress made in the months of November and December 2023.
Since the last report, 35 people contributed approximately 1500 code changes, focusing on bugfixes and improvements for the coming 24.02 release based on Qt6.
Transition to Qt6/KDE Frameworks 6As we plan for KDE Gear 24.02 to be our first Qt6-based release, there's been on-going work on more Qt6 porting, removing deprecated functions, removing support for the qmake build system, and so on.
New featureKontact, KMail, KAddressBook and Sieve Editor will now warn you when you are running an unsuported version of KDE PIM and it is time to update it. The code for this is based on Kdenlive.
ItineraryWhile the focus for Itinerary was also on completing the transition to Qt 6, with its nightly Android builds switching over a week ago, there also were a number of new features added, such as public transport arrival search, a new journey display in the timeline and a nearby amenity search. See Itinerary's bi-monthly status update for more details.

In KOrganizer it is no possible to search for events without specifying a time range (BKO#394967). A new configuration option was added to only notify about events that the user is organizer or attendee of. This is especially useful when users add a shared calendar from their colleagues, but don't want to be notified about events that they do not participate in. Korganizer intercepts SIGINT/SIGTERM signal. It will avoid to lose data during editing.
AkonadiWork has begun on creating a tool that would help users to migrate their Akonadi database to a different database engine. Since we started improving SQLite support in Akonadi during the year, we received many requests from users about how they can easily switch from MySQL or PostgreSQL to SQLite without having to wipe their entire configuration and setup everything from scratch with SQLite. With the database migrator tool, it will be very easy for users to migrate between the supported database engines without having to re-configure and re-sync all their accounts afterwards.
Dan's work on this tool is funded by g10 Code GmbH.
KMailThe email composer received some small visual changes and adopted a more frameless look similar to other KDE applications. In addition, the composer will directly display whether the openPGP key of a recipient exists and is valid when encryption is enabled.

The rust based adblocker received further work and adblock lists can be added or removed.

We removed changing the charset of a message and now only support sending emails as UTF-8. This is nowaday supported by all the other email clients. But we still support reading emails in other encoding.
Now kmail intercepts SIGINT/SIGTERM signal. It avoids to close by error KMail during editing.
Laurent finished to implement the "allow to reopen closed viewer" feature. This provides a menu which allows to reopen message closed by error.
In addition a lot of bugs were fixed. This includes:
- Fix bug 478352: Status bar has "white box" UI artifact (BKO#478352).
- Load on demand specific widget in viewer. Reduce memory foot.
- Fix mailfilter agent connection with kmail (fix apply filters)
A lot of work was done to rewrite the account wizard in QML. Accounts can now be created manually.
KAddressBookBug 478636 was fixed. Postal addresses was ruined when we added address in contact. (BKO#478636). Now KAddressbook intercepts SIGINT/SIGTERM signal. It avoids to close by error it during editing contact.
KleopatraDevelopment focussed on fixing bugs for the release of GnuPG VS-Desktop® (which includes Kleopatra) in December.
- OpenPGP keys with valid primary key and expired encryption or signing subkeys are now handled correctly (T6788).
- Key groups containing expired keys are now handled correctly (T6742).
- The currently selected certificate in the certificate list stays selected when opening the certificate details or certifying the certificate (T6360).
- When creating an encrypted archive fails or is aborted, then Kleopatra makes sure that no partially created archive is left over (T6584).
- Certificates on certain smart cards are now listed even if some of the certificates couldn't be loaded (T6830).
- The root of a certificate chain with two certificates is no longer shown twice (T6807).
- A crash when deleting a certificate that is part of a certificate chains with cycles was fixed (T6602).
- Kleopatra now supports the special keyserver value "none" to disable keyserver lookups (T6761).
- Kleopatra looks up a key for an email address via WKD (key directory provided by an email domain owner) even if keyserver lookups are disabled (T6868).
- Signing and encryption of large files is now much faster (especially on Windows where it was much slower than on Linux) (T6351).
2 bugs were fixed in sieveeditor:
- Fix BUG: 477755: Fix script name (BKO#477755).
- Fix bug 476456: No scrollbar in simple editing mode (BKO#476456).
Now sieveeditor intercepts SIGINT/SIGTERM signal. It avoids to close by error it during editing sieve script.
pim-data-exporterNow it intercepts SIGINT/SIGTERM signal. It avoids to close application during import/export.
37C3 Impressions
A week has passed since I attended the 37th Chaos Communication Congress (37C3) in Hamburg, Germany, together with a bunch of other KDE people.
For the first time KDE had a larger presence, with a number of people and our own assembly. We also ended up hosting the Linux on Mobile assembly as their originally intended space didn’t materialize. The extra space demand was compensated by assimilating neighbouring tables of a group that didn’t show up for the most part.
 KDE assembly featuring the event-typical colorful LEDs and sticker piles (photo by Victoria).
KDE assembly featuring the event-typical colorful LEDs and sticker piles (photo by Victoria).
Just for the logistical convenience of having a meeting point and a place to store your stuff alone this was a big help, and it also made a number of people find us that we’d otherwise probably wouldn’t have met.
TalksThere was one KDE talk in the main program, Joseph’s Software Licensing For A Circular Economy covering some of the KDE Eco work. I’d estimate about 500 attendees, despite the “early” morning slot.
Beyond that I actually managed to attend very few talks, Breaking “DRM” in Polish trains being clearly one of my favorites.
Emergency and Weather AlertsI got a chance to meet the author of FOSS Warn. FOSS Warn is a free alternative to the proprietary emergency and weather alert apps in Germany. That topic had originally motivated my work on UnifiedPush support for KDE, and an emergency and weather alert service that allows subscribing to areas of interest and receiving push notifications for new alerts, covering almost 100 countries.
The latter is a proof of concept demo at best though. The idea is to collaborate with the FOSS Warn team on a joint backend implementation, evolving this into something production-ready and usable for all of us.
While there’s still a couple of technicalities to resolve, after having met in person I’m very confident that this will all work out.
Open Transport CommunityOther groups I’m involved with were present at 37C3 as well, like the Open Transport community, with the Bahnbubble Meetup being the event that brought everyone together.
Discussion topics included:
- Identifying and getting access to missing data tables and documentations for DB and VDV ticket barcodes.
- Helping others with implementing the ERA FCB ticket format.
- Evolving the Transport API Repository.
- International collaboration and networking between the Open Transport communities in Europe,
- Integration between Itinerary and Träwelling.
- Train station identifiers in Wikidata, including a recent property proposal for DB station numbers, as well as a yet to be written one for IFOPT identifiers.
Many more topics ended up being discussed in parallel, overall I’d say there’s more than enough content and interested people for its own dedicated event/conference on this. Until somebody organizes that there’s the open-transport Matrix channel and the Railways and Open Transport track at FOSDEM.
Indoor Localization and RoutingThe OSM community was at 37C3 as well of course, and in that context I got one of the probably most unexpected contacts, by meeting one of the authors of simpleLoc. That’s an indoor navigation solution, which is one of the big open challenges in our indoor map view used in Itinerary.
Like other such solutions it’s unfortunately not fully available as Free Software, but the available information, components and published papers nevertheless turned out very valuable, in particular since this is using a localization approach that requires only commonly available smartphone sensors.
Much more immediately applicable were the hints on how they implemented indoor routing. Unlike for “outdoor” navigation graph-based algorithms are usually not an option, we need something that works on polygons in order to use OSM data as input directly. Existing solutions I encountered for that in a mapping/geography context were all proprietary unfortunately, but there’s a free library that solves that problem for 3D game engines: Recast Navigation.
While I’m not entirely sure yet how to map all relevant details to that (e.g. directional paths for escalators, tactile paving guides, etc), the initial experiments look very promising.
 Routing through a complex indoor corridor.
Routing through a complex indoor corridor.
There’s obviously a ton of work left, as this essentially requires mapping all relevant bits of OSM indoor data to a 3D model, and that’s at the very limit of what can be extracted from the OSM data and data model in many places.
KDE OutreachWhile people working on technology make up a significant part of the audience of 37C3, there’s many more people from other areas attending as well, so this also was an opportunity for a bit of user research, following the pattern of the kde.org/for pages.
KDE for activistsOn the KDE for Activists page we focus a lot on tools for secure and self-hosted infrastructure. The need for that seems like a given or even a hard requirement for people in that field, not something that needs to be argued for (the event itself might provide a certain selection bias for that though).
What we however need to improve on is making this much more robust and easy to setup and manage for people that might not be familiar with all the technical details, jargon and abbreviations we expose them to. Even worse, that can pose the risk of making dangerous mistakes, up to causing people physical harm.
KDE for FOSS projectsMeeting other FOSS developers is also interesting, in particular those not well connected to our usual bubble. That’s often single person projects, some of them even quite successful ones. Around those KDE is then the odd outlier, due to our size and choice of tools/infrastructure (ie. not Github).
Topics that typically come up then are handling of finances, legal risks/liability, shortcomings of Github, moderation of communication channels, etc., all things far less painful from the perspective of someone under the umbrella of a big organization like KDE.
I think there’s some interesting discussions to be had on how widely we want to extend the KDE umbrella and how we want to promote that, what other umbrella organizations there are and whether there are still uncovered gaps between those, and how to manage the scope and governance of such umbrella organizations.
It’s probably also worth talking more about what we already have and do in that regard, it’s not even clear to everyone apparently that joining a larger organization is even an option.
KDE for public administrationWe got questions for pointers to material/support for doing medium-sized Linux/Plasma deployments in public administration. This is unfortunately something we don’t have anywhere in a well structured form currently I think.
It would seem very useful to have, beyond a KDE focus even. There’s people on the inside fighting for this, and while the upcoming Windows 11 induced large-scale hardware obsolescence is working in our favor there, the increasingly pervasive use of MS Teams is making a migration to FOSS infrastructure and workspaces much harder.
ConclusionI had very high expectations for this after the experience at 36C3, but by day 3 this had exceeded all of them. The extreme breadth of people there is just unmatched, coming from FOSS/Open Data/Open Hardware projects tiny to large, public administration and infrastructure, education/universities, funding organizations, politics and lobbying, civil/social initiatives, you name it.
And all of that in a fun atmosphere that never stops to amaze. While walking down a corridor you might find yourself overtaken by a person driving a motorized couch, and if you have an urgent need for an electron microscope for whatever reason someone over in the other hall brought one just in case. And all of that is just “normal”, I could fill this entire post with anecdotes like that.
Ideas and plans for 38C3 were already discussed :)
New Video: Krita 5.2 Features!
Ramon Miranda has published a new video on the Krita channel: Krita 5.2 Features. Take a look and learn what’s new in our latest release:
The post New Video: Krita 5.2 Features! appeared first on Krita.
Two Breeze Icon Updates
Hi all,
I made a couple of videos explaining more updates for Breeze icons. Enjoy!
Gaming only on Linux, one year in
I have now been playing games only on Linux for a year, and it has been great.
With the GPU shortage, I had been waiting for prices to come back to reasonable levels before buying a new GPU. So far, I had always bought NVIDIA GPUs as I was using Windows to run games and the NVIDIA drivers had a better “reputation” than the AMD/Radeon ones.
With Valve’s Proton seriously taking off thanks to the Steam Deck, I wanted to get rid of the last computer in the house that was running Microsoft Windows, that I had kept only for gaming.
But the NVIDIA drivers story on Linux had never been great, especially on distributions that move kernel versions quickly to follow upstream releases like Fedora. I had tried using the NVIDIA binary drivers on Fedora Kinoite but quickly ran into some of the issues that we have listed in the docs.
At the time, the Universal Blue project did not exist yet (Jorge Castro started it a bit later in the year), otherwise I would have probably used that instead. If you need NVIDIA support today on Fedora Atomic Desktops (Silverblue, Kinoite, etc.), I heavily recommend using the Universal Blue images.
Hopefully this will be better in the future for NVIDIA users with the work on NVK
So, at the beginning of last year (January 2023), I finally decided to buy an AMD Radeon RX 6700 XT GPU card.
What a delight. Nothing to setup, fully supported out of the box, works perfectly on Wayland. Valve’s Proton does wonders. I can now play on my Linux box all the games that I used to play on Windows and they run perfectly. Just from last year, I played Age of Wonders 4 and Baldur’s Gate 3 without any major issue, and did it pretty close to the launch dates. Older titles usually work fairly well too.
Sure, some games require some little tweaks, but it is nothing compared to the horrors of managing a Windows machine. And some games require tweaks on Windows as well (looking at you Cyberpunk 2077). The best experience is definitely with games bought on Steam which usually work out of the box. For those where it is not the case, protondb is usually a good source to find the tweaks needed to make the games work. I try to keep the list of tweaks I use for the games that I play updated on my profile there.
I am running all of this on Fedora Kinoite with the Steam Flatpak. If you want a more console-like or Steam Deck-like experience on your existing computers, I recommend checking out the great work from the Bazzite team.
Besides Steam, I use Bottles, Cartridge and Heroic Games Launcher as needed (all as Flatpaks). I have not looked at Origins or Uplay/Ubisoft Connect games yet.
According to protondb, the only games from my entire Steam library that are not supported are mostly multiplayer games that require some specific anti-cheat that is only compatible with Windows.
I would like to say a big THANK YOU to all the open source graphics and desktop developers out there and to (in alphabetical order) AMD, Collabora, Igalia, Red Hat, Valve, and other companies for employing people or funding the work that makes gaming on Linux a reality.
Happy new year and happy gaming on Linux!
Cleaning up KDE's metadata - the little things matter too
Lots of my KDE contributions revolve around plugin code and their metadata, meaning I have a good overview of where and how metadata is used. In this post, I will highlight some recent changes and show you how to utilize them in your Plasma Applets and KRunner plugins!
Applet and Containment metadataApplets (or Widgets) are one of Plasma's main selling points regarding customizability. Next to user-visible information like the name, description and categories, there is a need for some technical metadata properties. This includes X-Plasma-API-Minimum-Version for the compatible versions, the ID and the package structure, which should always be “Plasma/Applet”.
For integrating with the system tray, applets had to specify the X-Plasma-NotificationArea and X-Plasma-NotificationAreaCategory properties.
The first one says that it may be shown in the system tray and the second one says in which category it belongs. But since we don't want any applets
without categories in there, the first value is redundant and may be omitted! Also, it was treated like a boolean value, but only "true" or "false" were expected.
I stumbled upon this when correcting the types in metadata files.
This was noticed due to preparations for improving the JSON linting we have in KDE. I will resume working on it and might also blog about it :).
What most applets in KDE specify is X-KDE-MainScript, which determines the entrypoint of the applet.
This is usually “ui/main.qml”, but in some cases the value differs. When working with applets, it is confusing to first have to look at the
metadata in order to find the correct file. This key was removed in Plasma6 and the file is always ui/main.qml.
Since this was the default value for the property, you may even omit it for Plasma5.
The same filename convention is also enforced for QML config modules (KCMs).
What all applets needed to specify was X-Plasma-API. This is typically set to "declarativeappletscript", but we de facto never used its value, but enforced it being present. This was historically needed because in Plasma4, applets could be written in other scripting languages. From Plasma6 onward, you may omit this key.
In the Plasma repositories, this allowed me to clean up over 200 lines of JSON data.
metadata.desktop files of Plasma5 addonsJust in case you were wondering: We have migrated from metadata.desktop files to only metadata.json files in Plasma6.
This makes providing metadata more consistent and efficient. In case your projects still use the old format, you can run desktoptojson -i pathto/metadata.desktop
and remove the file afterward.
See https://develop.kde.org/docs/plasma/widget/properties/#kpackagestructure for more detailed information. You can even do the conversion when targeting Plasma5 users!
Another nice addition is that “/runner” will now be the default object path. This means you can omit this one key. Check out the template to get started: https://invent.kde.org/frameworks/krunner/-/tree/master/templates/runner6python. DBus-Runners that worked without deprecations in Plasma5 will continue to do so in Plasma6! For C++ plugins, I will make a porting guide like blog post soonish, because I have started porting my own plugins to work with Plasma6.
Finally, I want to wish you all a happy and productive new year!
Tellico 3.5.3 Released
Tellico 3.5.3 is available, with a few minor clean-ups.
Improvements and Bug Fixes- Improved some entry matching heuristics when updating from other sources.
- Updated the author search for the Open Library data source.
- Updated Kino-Teatr data source.
- Fixed compilation for versions of KDE Frameworks < 5.94.
- Fixed layout bug in Fancy template for custom collections with no image.
Breeze Icons Update!
A few weeks ago, right before the holidays, some chatter in the VDG channel happened where the desire to change our icons to a 24x24px size came up.
Most modern interfaces use this icon size as a base. Plasma has been encouraged many times to adopt this size. However, manpower is always something not readily available.
The conversation picked my interest. In the past, I have worked making icons using Inkscape. At the time, the interface didn’t have all the shortcut helpers that it does today. Also, with the advent of UI-specific graphical applications like Figma and Penpot, I figured it might be much easier to edit icons today than in the past. I am talking many years, FYI.
With this in mind, I downloaded a copy of the most current Breeze icon collection, accessed the 22px folder for actions and begun editing.
At first sight, most might think this is just a matter of mass-resizing from 22 to 24 and merge. However, the reality is much different. These icons feature mostly 1px lines. They also contain pixel fractions that lead to misalignment and blurriness. Since we don’t have the actual graphical original files, as they have been flattened in export, the shapes are only workable through editing nodes, which is a pain!
Another issue is that our Breeze icons contain a css sheet that correlates colors to colors in Plasma. This allows for easy color transformations on the system without much hassle. However, graphical applications like Figma and Penpot remove the css.
For this reason @manuelijin created a nice plugin for Figma called Icon Jetpack. This plugin will allow designers to export the updated icons with all the necessary pieces for production.
In the public Figma file, I created the colors needed for action icons and they are now embedded into the exported file.
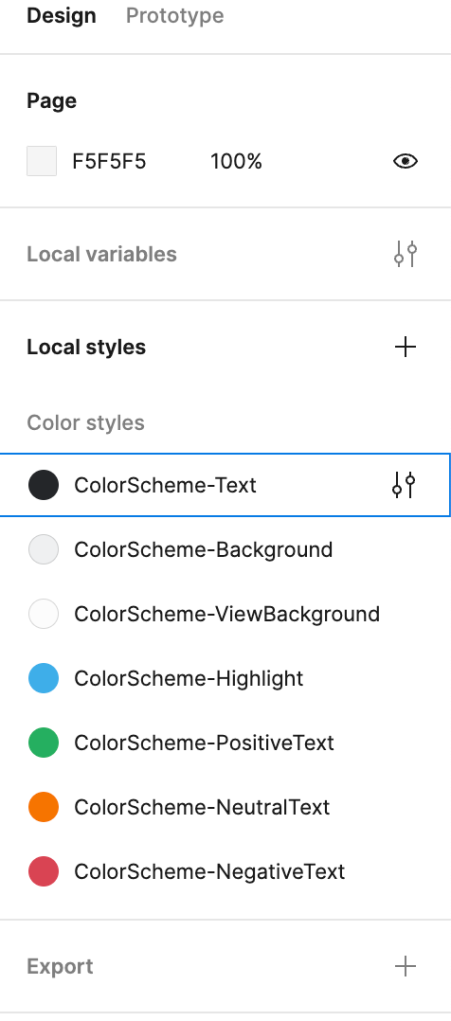
Another criticism of our current icons we would like to address is how thin they feel in high-DPI screens. To address this, we have been making our lines 2px (for the most part) where it makes sense.
Given this is an update, and who knows how long it will take for another time when an update is done, I also feel it’s necessary to update many of the shapes we have. We are using rounding for making shapes a little more approachable. Some icons have been transformed inspired by the original files. For other files, I usually check on other icon providers to see how different or similar we are to most icons today. That way, if there is a need for more editing, we can land on something recognizable.
The editing process that seems the fastest involves recreating the shapes, using an icon grid, aligning to the grid as much as possible, reusing icons for consistency. This should help future designers consult the Figma file and edit en-masse.
For now, we are in the middle of editing icons. My intention is that we do a first pass and seek feedback. Do another refinement pass and then see how the community reacts to the edits. Hopefully the work is useful and can be merged eventually.
We have a total of 1206 icons. So far, we have edited 262.
Here is a before/after:
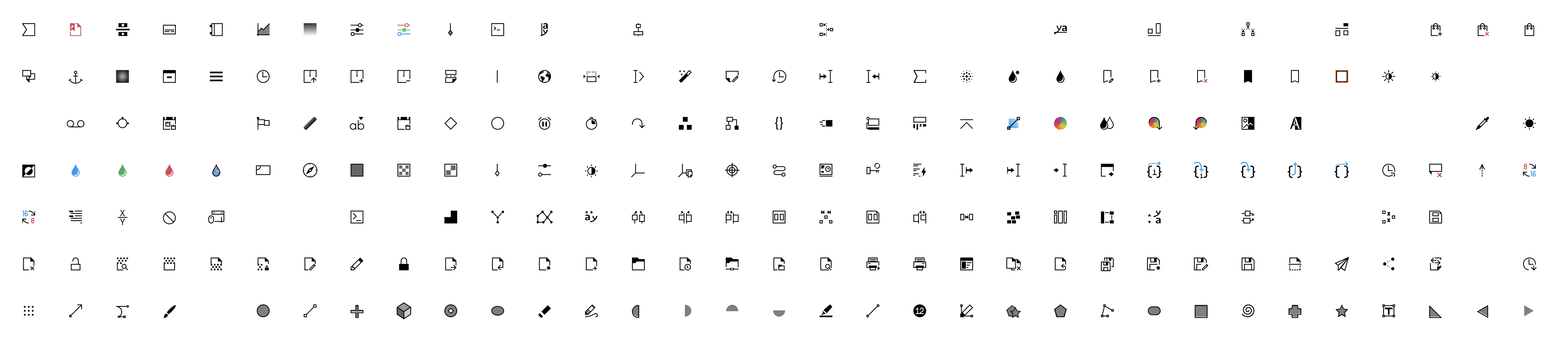

There are some more edits at the bottom of the file that I didn’t include.
Hope you like.
I also made a couple of videos to show the process and see if any other designers would like to contribute some time to update the icons.
My work in KDE for December 2023
This is a lighter month due to holidays (and also I’m trying not to burn out), but I tried to fit in a bit of KDE anyway. It’s all bugfixes anyway because of the feature freeze!
Not mentioned is a bunch of really boring busywork like unbreaking the stable branches of Gear applications due to the CI format changing.
Tokodon #Bugfix Fixed a bunch of papercuts with the Android build, and the new nightlies should be appearing in the F-Droid repository soon! It’s mostly adding missing icons and making sure it looks good in qqc2-breeze-style (the style we use on Android and Plasma Mobile.) 24.02
Bugfix Fixed Akkoma and Pleroma tags not being detected correctly, they should open in Tokodon instead of your web browser again! 24.02
Plasma #Bugfix KScreenLocker CI now runs supported tests, see the KillTest fixes and pamTest fix. Failing tests also make the pipeline visibly fail, as it should. (Unfortunately, the pipeline as of writing fails to due some unrelated regression?) 6.0
Bugfix The lockscreen greeter now handles even the fallback theme failing, and display the “please unlock using loginctl” message instead of a black screen. 6.0
Bugfix Improves the QtQuickControls style selection mechanism to work around a possible regression in Qt6. This should stop applications from mysteriously not opening in the rare (but unsupported) cases where our official styles aren’t installed/loading. 6.0
Kirigami #Bugfix Fixed a bunch of TextArea bugs that affected mobile form factors, such as Plasma Mobile and Android. This is mostly for Tokodon (because we abuse TextAreas a lot in scrolling content) but it can help other applications too! The selectByMouse property is now respected, the cursor handles should show up less. 6.0
Bugfix Invisible MenuItems in qqc2-breeze-style are collapsed like in qqc2-desktop-style. Mobile applications should no longer have elongated menus with lots of blank space! 6.0
Bugfix You can finally right-click with a touchpad in qqc2-desktop-style TextFields again! This bug has been driving me up a wall when testing our Qt6 stuff. 6.0
Feature When the Kirigami theme plugin fails to load, the error message will soon be a bit more descriptive. This should make it easier for non-developers to figure out why Kirigami applications don’t look correct. 6.0
Android #Bugfix Fixed KWeather not launching on Android because it needed QApplication. I didn’t know QtCharts is QWidgets-based! 24.02
I also went around and fixed up a bunch of other mobile applications with Android contributions too small to mention. Applications like Qrca, Kongress, etc.
NeoChat #Bugfix Prevent the NeoChat notification daemon from sticking around forever although that should rarely happen. 24.02
Outside of KDE #Nagged for a new QtKeychain release due to a critical bug that would cause applications to never open KWallet5. Please also nag your distributions to package 0.14.2 soon! Anything using QtKeychain 0.14.1 or below won’t work in Plasma 6. This doesn’t affect people in the dev session, because QtKeychain should be built from git.
Helping the Gentoo KDE Team with packaging Plasma 6 and KDE Gear 6. I managed to update my desktop to Plasma 6 and submitted fixes to get it closer to working. I also added Arianna, PlasmaTube and MpvQt packages.
Web Review, Week 2023-52
Let’s go for my web review for the week 2023-52.
Drivers of social influence in the Twitter migration to Mastodon | Scientific ReportsTags: tech, social-media, sociology, psychology, community, fediverse, twitter
Despite understandable limitations, this studies has a few interesting findings on how communities can more easily switch platforms (in this case from Twitter to Mastodon). At least one is a bit counter-intuitive.
https://www.nature.com/articles/s41598-023-48200-7
Tags: tech, moderation, social-media
Another platform failing at proper moderation…
https://www.theverge.com/2023/12/21/24011232/substack-nazi-moderation-demonetization-hamish-mckenzie
Tags: tech, social-media, google, research
An important question for proper statistics about the content itself. Surprisingly harder to get an answer to it than one would think.
https://ethanzuckerman.com/2023/12/22/how-big-is-youtube/
Tags: tech, ai, machine-learning, gpt, copyright, law
It was only a question of time until we’d see such lawsuits appear. We’ll see where this one goes.
Tags: tech, ai, machine-learning, gpt, economics, energy, ecology
Very interesting paper about the energy footprint of the latest trend in generator models. The conclusion is fairly clear: we should think twice before using them.
https://www.sciencedirect.com/science/article/pii/S2542435123003653#fig1
Tags: tech, ai, machine-learning, gpt, school, learning, education
When underfunded schools systems preaching obedience and conformity meet something like large language models, this tips over the balance enough that no proper learning can really happen anymore. Time to reform our school systems?
Tags: tech, blog, self-hosting, attention-economy
Definitely true… never had use for more than the server logs for understanding the traffic on my blog. No need to invade the privacy of people through their browser.
https://blog.yossarian.net/2023/12/24/You-dont-need-analytics-on-your-blog
Tags: tech, mobile, qt, android, ios
The experience is still not great on iOS and Android. This is in part due to the platforms design though, this still make Qt a great fit when you control the platform like for Plasma Mobile. For less friendly platforms this still limits the use to cases where you already have quite some Qt code. Still the same situation than a few years ago.
https://camg.me/qt-mobile-2023/
Tags: tech, javascript, type-systems, bug, quality
Interesting study, the amount of bugs which could have been prevented by the introduction of static typing in Javascript code bases is definitely impressive (15% is not a small amount in my opinion).
https://discovery.ucl.ac.uk/id/eprint/10064729/1/typestudy.pdf
Tags: tech, git, version-control
It looks like git workflows using rebase are becoming the norm. People are actively trying to avoid merge commits in their repository history. Tooling support could be a bit better though.
https://graphite.dev/blog/why-ban-merge-commits
Tags: tech, css
Interesting guidelines for organizing CSS. This should avoid making things too much of a mess.
https://ricostacruz.com/rscss/
Tags: tech, graphics
Exploration of the causes of color banding and how to work around them.
https://blog.frost.kiwi/GLSL-noise-and-radial-gradient/
Tags: tech, mozilla, observability, telemetry, profiling, optimization, performance
Very nice collection of stories from the trenches of Firefox development. Lots of lessons learned to unpack about optimizing for the right thing, tooling, telemetry and so on.
https://yoric.github.io/post/so-you-want-to-optimize-your-code/
Tags: tech, tools, craftsmanship, developer-experience
It’s indeed important to hone your tools as well. Even though most things are not blocked due to tools, the right ones when well designed can make things easier.
https://two-wrongs.com/john-the-toolmaker
Tags: tech, complexity, reliability
Word of caution on how we tend to reason about complex systems. They don’t form a chain but a web, and that changes everything to understand how they can break.
https://surfingcomplexity.blog/2023/12/23/on-chains-and-complex-systems/
Tags: tech, dependencies, maintenance
This is an interesting metaphor. I’ll try to keep it in mind.
https://dubroy.com/blog/cold-blooded-software/
Tags: tech, community, smells, organization, quality
This study does a good job looking at the impact of community smells over the presence of code smells. This is an excellent reminder that the organization influences greatly the produced code.
Tags: tech, linkedin, developer-experience, metrics, productivity
Interesting framework. I wouldn’t take everything at face value, but this looks like a good source of inspiration to design your own.
https://linkedin.github.io/dph-framework/
Tags: tech, management, leadership
A bit too archetypal for my taste but there’s some truth to it. If you lean towards “explorer” (I think I do), it’s hard to be also a leader. Now you could be aware of your flaws and put tools in place to compensate for them when you need lead.
Bye for now! And see you in 2024!