Desktop applications for 'Information Management' that go beyond conventional card-index style databases are hard to find. The ideas behind such software are perhaps not that well known, so a prototype program, Knowledge, has been developed to put them firmly into the public domain.
Fields in any record can be arbitrarily changed.
The why
'Idealist' - a long-discontinued program developed for Windows by the publishers Blackwell - was taken as a source of inspiration. This type of software indexes text as it is entered and allows rapid text searching, making it useful for storing notes and observations as well as archival information. Users of Idealist included museums, medical practices for storing patient records, academics for bibliographic databases, and even by the police for use in investigations. Nowadays there is specialist commercial software for many of these purposes, but for individuals who want a straightforward desktop application for building up databases of the things that interest them there is little to choose from. This is despite the fact that libraries for text searching, such as Xapian and Lucene, are now freely available.
The how
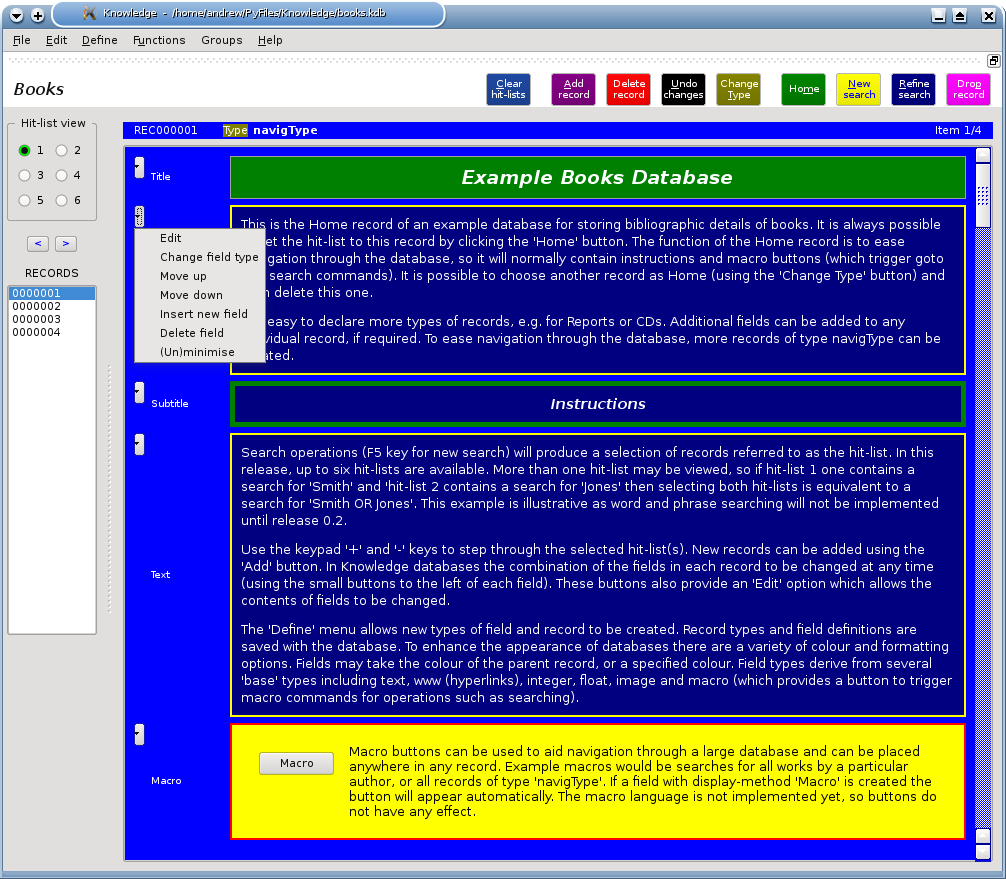
Knowledge was coded in Python to save development time and, while incomplete, allows the ideas behind Information Management software to be explored. Knowledge goes beyond existing KDE applications for storing textual information in a searchable format (Knotes etc.) because the data is stored in a highly structured way, which provides many possibilities for both the GUI display of data, and for searches. The data is stored in records, but unlike most other databases these are flexible as fields within each can be arbitrarily added, removed or re-ordered.

Dialogue for defining field types.
Each type has associated style information (colour etc.).
Field and record type definitions are saved with the database.
Each field contains data of a certain type, such as text, an image, a web address, or a number. Most field types allow a caption to be stored with the data. Search operations for integers, floats and dates have been implemented; text searches are not yet available. The user must define the fields that are needed, for example Year (integer), Cost (float), Author (text), Title (text) etc. These definitions are stored with the database. Each field type has its own style settings, so for example Author fields can be declared to be green with italic text. The user must also define Record types, and a default combination of fields for each. These are used in search operations, for example it is possible to search the entire database for Records that contain a Year field that contains a value between 1989 and 1996, or the search can be restricted to Records of a particular type, 'bookType' perhaps. It is possible to have Records of many different types within a database. Search operations produce a hit-list of records, which can be stepped through with the keypad + and - keys.
Every Knowledge database has a 'Home' Record - and there is button to set the hit-list to this record. The Home Record typically contains navigation information to help the user. 'Macro' fields can be included in any record, but are especially useful in the home Record. In a Macro field, a button is displayed, which the user may click to execute some commands which the user has defined for that field.
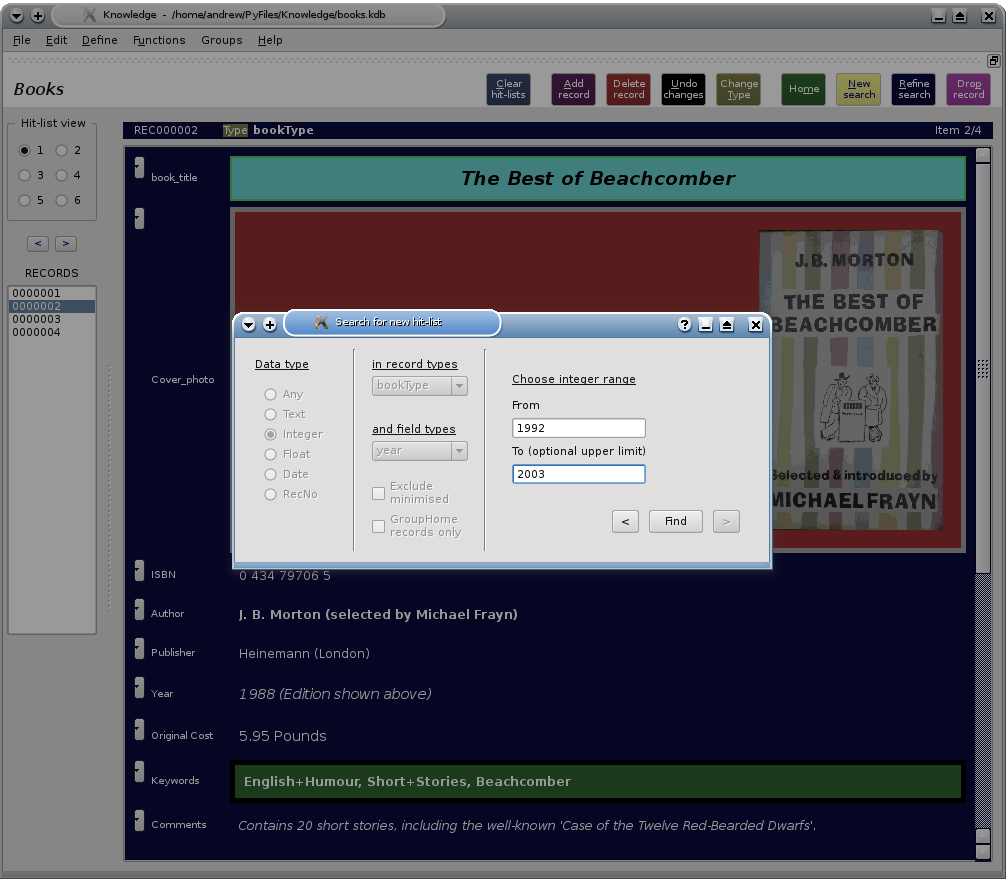
Using the search dialogue to perform a search for an integer.
In this example, records of type 'bookType' that contain a
'Year' field will be searched. Those records
for which the Year field contains a value between 1992
and 2003 will be placed in the hit list. Float and integer searches
are fully implemented in the current release.
Typically these are search commands to create a new hit-list (perhaps all Records of type 'bookType'), or perhaps just to display a record that contains hints for using that database. This feature (also borrowed from Idealist) helps the user to structure their data, and helps to aid navigation for large databases. The Macro language is not implemented as yet - but the power of the idea should be evident.

Using the search dialogue to perform word or phrase searching.
In this example, all text fields in records of type 'bookType' will
be searched. Records that contain a text field that contains
the word or phrase will be placed in the hit list. NB: The text
indexing system is not yet implemented so text searches
do not yet work.
Status
Writing the prototype database has taken one year (including the time to get to grips with Qt and SQL). The project is too large for a part-time project, and now that the prototype is far enough advanced to allow the ideas to be readily understood it is time to try to attract the attention of some experienced KDE developers. The prototype program uses the Qt libraries, but the desire is to switch it to KDE libs to make full use of KDE facilities. The author can be contacted via kde-apps (user agkdb) but currently a cool project webpage is lacking. So besides developers interested in working on Knowledge, anyone who wants to set up such a page is more than welcome!
Comments
Why don't you use Nepomuk ?
ASeigo would not be pleased to know about that -
http://aseigo.blogspot.com/2010/05/i-dont-need-no-stinking-nepomuk-right...
:>
Yeah, whenever you feel like this is getting close to release or whatever, you should really contact one of the KDE artwork guys to make it look a little nicer.
It might be awesome tech, but as apple has shown everybody, you get users and therefore exposure and growth by the shiny factor.
As far as I can see Nepomuk is not an application as such, but is a library that can be used for collating and searching metadata from KDE applications. The website cited above contains a diverse range of opinions on Nepomuk and I do not feel able to comment in detail. I would guess that Nepomuk is chiefly used for PIM applications, such as calendars, address books, email software etc. Knowledge is designed to store records on subjects of study e.g. for academic notes, ornithological observations, collections of almost anything etc. Knowledge databases are potentially very large, and so data is held in a very structured way to ease navigation. Furthermore, 'macro' fields can be included anywhere in the database as a navigational tool. You will probably need to try the software to understand this idea.
I have been very happy all day, after I found this information. Some years ago I (and others of my acquaintance) used Idealist a great deal for research and found it invaluable - I never found a replacement that worked in quite the same way. I know somebody who used Idealist to write a book on plant taxonomy (it contained a lot of information that fell within a prescribed number of fields). Although I don't use Idealist anymore, because I moved to Linux, I still have it tucked away somewhere... I am exploring Knowledge and look forward to seeing it being developed further. To those of you who have never used software like this, there is nothing quite like it - truly invaluable. I shall be following this project closely.
My grateful thanks to the author!
Thank you for the comments, which I agree with entirely. Blackwells' Idealist is as you say invaluable as a research tool, but is also useful for more humdrum purposes, e.g suppliers, contacts etc. One of the challenges for me is to get across the idea that this type of software really can do so much more than many other database programs.
Incidentally, according to this blog Idealist will run under Linux using Wine. http://osbloggery.blogspot.com/2007/12/after-idealist.html
I hope to continue with development on this program, but I do need to attract some good coders, particularly for the database/ searching functions. Suggestions for a memorable name for the software would also be welcome.
Andrew
I don't know how to code in what you need, so can't help there but would be happy to help with the help system once you are a little further down the road.
I have just checked and I can install and run (and open my old databases) Idealist on Ubuntu using Wine.
Am thinking about the name and will let you know!
Best, Martin